Cloud cost optimisation is just a fancy term for a simple idea: continuously trimming your cloud bill without hurting performance, reliability, or security. Think of it as financial hygiene for your cloud environment, it’s all about making sure you only pay for what you actually use.
What Is Cloud Cost Optimisation Really

Let's bring this down to earth. You wouldn't leave every light in your house on 24/7 or crank up the heating when nobody's home, right? That would be just burning money. The exact same logic applies to your cloud setup.
Lots of companies jump into the cloud for its amazing flexibility, but they quickly get sticker shock when the bills start rolling in. Why? More often than not, they're paying for resources that are just sitting idle or are way more powerful than they need to be.
Cloud cost optimisation is the discipline of hunting down and eliminating that waste. It’s not about slashing costs recklessly; it’s about squeezing the most business value out of every single dollar you spend on the cloud. And it's a big deal. Some reports show that as much as 32% of all cloud spending is completely wasted. That's a huge chunk of cash that could be fuelling growth and innovation instead.
This whole process requires a shift in mindset. You have to move from a reactive "Oh no, the bill's too high!" scramble to a proactive culture where everyone feels accountable for costs. It's about asking the tough questions before, during, and after a resource is launched.
The Core Purpose of Optimisation
At its heart, cloud cost optimisation is about one thing: efficiency. It's the bridge that connects your technical teams, who are spinning up resources, with the finance teams who have to pay the bills. The goal is to create a world where engineers can build and innovate freely but are also clued into the financial impact of their decisions.
This is a world away from simple cost-cutting. Hacking away at your bill without a plan can easily lead to poor performance or security holes. True optimisation is a balancing act. It ensures your apps have all the power they need to run flawlessly while systematically getting rid of the excess that's bloating your invoice.
The goal isn’t just to cut waste. It's about boosting the operational excellence and performance of your cloud resources. By using data and analytics, you can pinpoint the best resource configurations and pricing models for your specific needs.
Common Culprits of Cloud Waste
The first step to fixing the problem is knowing where the money is leaking from. While every cloud environment has its own quirks, a few usual suspects are responsible for most of the unnecessary spending. These are often the low-hanging fruit, the easy wins that can give you immediate savings.
Common sources of waste include:
- Idle Resources: These are the "zombie" assets of the cloud world. Think of virtual machines left running long after a project has wrapped up, storage volumes that aren't attached to anything, or ancient data snapshots nobody needs. They deliver zero value but keep racking up charges, month after month.
- Overprovisioned Instances: This is a classic. It happens when you use a resource that's far too big or powerful for the job it's doing. Picture a simple dev server that only needs two CPU cores but is running on a monster eight-core machine. You're paying for capacity that you'll never touch.
This is all part of a bigger strategy called cloud cost management. For a closer look, you can explore our guide on what is cloud cost management and how to do it. Nailing these basics sets the stage for the more advanced strategies we’ll cover, turning optimisation from a tedious IT chore into a powerful business advantage.
How to Find and Eliminate Hidden Cloud Waste

Starting your cloud cost optimization journey is a lot like being a detective. You need a simple playbook for hunting down the biggest sources of waste hiding in your cloud accounts. The good news? Most of it comes from just a handful of very common culprits.
If you focus on these areas first, you'll score some quick wins, show immediate savings, and build momentum for a more sophisticated strategy down the road. The two problems draining more budgets than any others are idle resources left running 24/7 and instances that are way too powerful for the job they're doing.
And these problems are everywhere. Industry research shows that companies waste up to 32% of their cloud spend. The primary causes? Idle or underused resources (66%) and overprovisioned capacity (59%). That’s a massive opportunity for savings just by cleaning up what you already have. You can see more on these cloud cost optimization trends for 2025 on scalr.com.
Spotting and Shutting Down Idle Resources
Idle resources are the digital version of leaving the lights on in an empty office building. You’re paying for them by the hour, but they’re delivering zero business value. These "zombie" assets pop up all the time, especially in dynamic dev and test environments where things get spun up and then forgotten about.
Your first mission is to hunt down and terminate these budget-killers. The best way to make sure nothing slips through the cracks is to run a systematic audit.
Start by looking for these specific types of idle assets:
- Unattached EBS Volumes: Think of these as hard drives that aren't plugged into any computer. They often get left behind when a virtual machine is terminated, quietly racking up storage costs month after month.
- Old Snapshots: Backups are critical, but snapshots can pile up fast. Take a hard look at your retention policies and delete any old ones that are no longer required for recovery or compliance.
- Idle Virtual Machines: These are the servers that were spun up for a project, a quick test, or a developer sandbox and were simply never turned off. They're a huge source of waste, and shutting them down is a critical first step. You can learn more about the hidden cost of idle VMs in our article.
A regular cleanup schedule is your best defense. Put a recurring reminder on your calendar, monthly or quarterly, to run an audit of your cloud environment with the sole purpose of finding and eliminating these idle resources.
Tackling Overprovisioned Instances
Overprovisioning is a sneakier problem, but it’s just as expensive. This is what happens when you pick a resource that's much bigger and more powerful than what the workload actually needs. It’s like using a sledgehammer to crack a nut, you’re paying for horsepower you never use.
This usually comes from a "better safe than sorry" mindset, where engineers pick oversized instances just in case, to avoid any performance problems. But with today’s monitoring tools, you can base these decisions on hard data, not guesswork.
To find overprovisioned resources, you have to look at their actual performance metrics over time. Hunt for instances that show consistently low utilization.
Key Metrics to Analyze
- CPU Utilization: If a machine's average CPU usage is consistently hanging out below 20%, it's a perfect candidate for downsizing.
- Memory Usage: It's the same story with memory. If an instance is only using 30% of its available RAM, it’s almost certainly overprovisioned.
- Network I/O: Look at the traffic patterns. A machine built for high network throughput that barely sees any action can be moved to a smaller, cheaper instance type.
By methodically checking these metrics, you can "rightsize" your instances, matching their specs precisely to what the workload demands. This one move can lead to savings of 40% or more on individual resource costs, making it a cornerstone of any successful cloud cost optimization plan.
Mastering Proactive Cost Control Strategies
The best way to get a handle on your cloud bill isn't by scrambling to clean up messes after the fact. Instead of waiting for a surprisingly high invoice to trigger a panic audit, the real secret is to build cost efficiency directly into your day-to-day operations. It’s a shift from putting out fires to preventing them in the first place.
Three core strategies are the foundation of this proactive approach: rightsizing your resources, scheduling environments to turn off when they're not needed, and adopting modern, cost-efficient architectures. Each one strikes a different balance between the effort you put in and the savings you get out, letting you create a layered defense against wasted cloud spend.
This infographic gives a great visual breakdown of the effort you can expect to put in versus the potential savings for each of these key strategies.
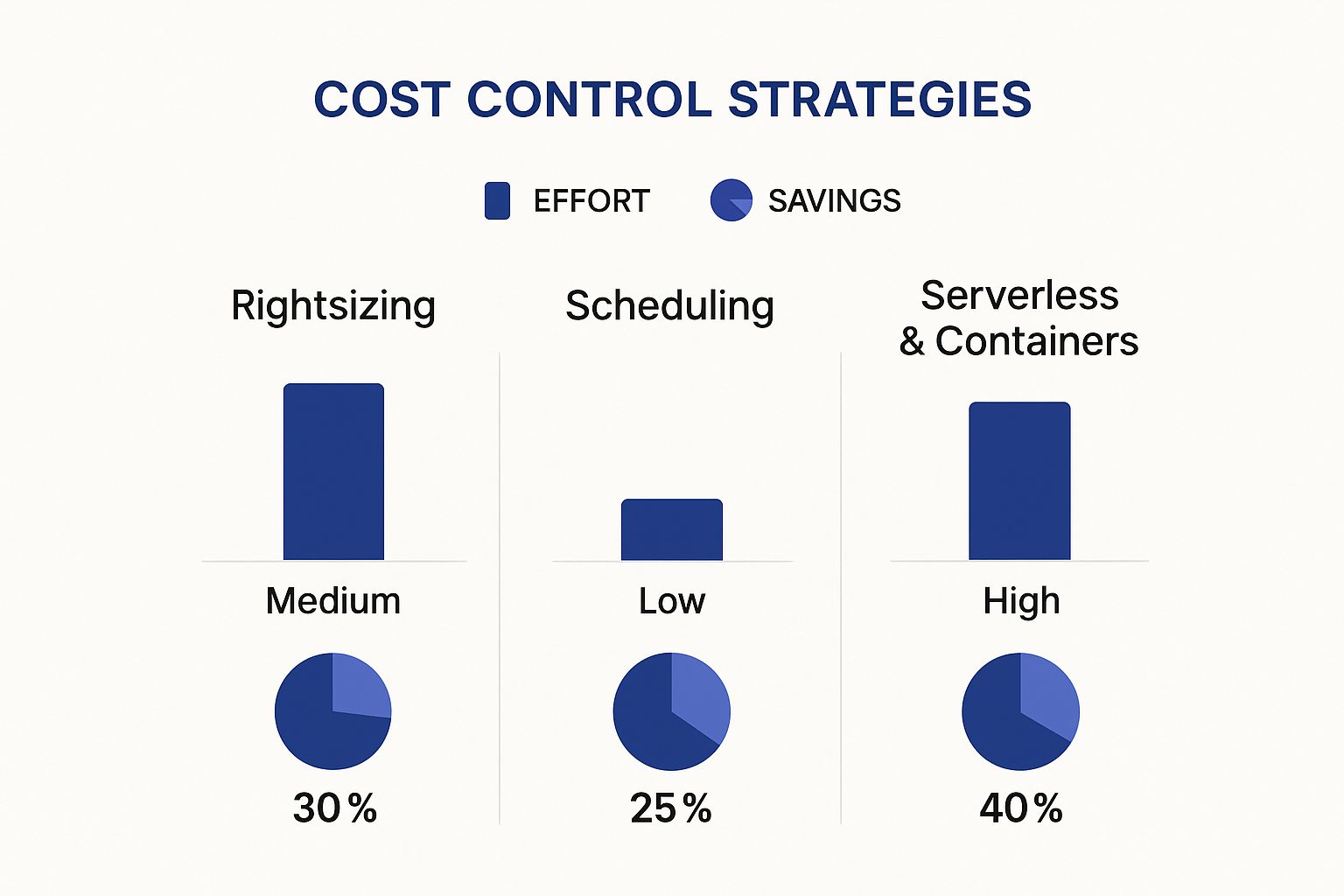
As you can see, jumping straight to modern architectures like serverless can deliver the biggest savings, but it also demands the most significant upfront work. On the flip side, scheduling offers a fantastic return for a relatively small amount of effort, making it a perfect place to start.
What Is Rightsizing Really About?
People often hear "rightsizing" and just think it means shrinking everything. But it's more nuanced than that. True rightsizing is about perfectly matching the size and type of a cloud resource to what the workload actually needs. It's about paying for exactly what you use, no more, no less.
Sometimes, this does mean downsizing an oversized virtual machine that’s barely breaking a sweat with low CPU usage. But it could just as easily mean upgrading a resource that's constantly maxed out and struggling. After all, poor performance has its own costs, from a terrible user experience to lost business.
The goal is to stop guessing and start making data-driven decisions. By looking at performance data like CPU utilization, memory usage, and network traffic over time, you can confidently pick the right instance for the job. This way, you’re not just cutting costs; you're also making sure your applications run smoothly.
Rightsizing isn’t a one-and-done task. It's a continuous loop. As your application's needs change or new, more efficient instance types become available, you should always be re-evaluating to make sure you still have the perfect fit.
The Power of Scheduling Non-Production Environments
One of the simplest yet most powerful moves you can make is resource scheduling. It’s exactly what it sounds like: automatically shutting down resources when nobody is using them. This is an absolute game-changer for non-production environments.
Think about your development, testing, staging, and QA environments. Do they really need to be running 24/7? For almost every company, the answer is a hard no. These servers are typically only needed during business hours, Monday to Friday.
Just by turning them off overnight and on weekends, you can unlock massive savings. An environment running for 40-50 hours a week instead of the full 168 hours will see its costs plummet by over 70%. That's a huge win for very little technical effort.
Here are a few prime candidates for scheduling:
- Development Servers: Your developers aren't coding around the clock. Power down their sandboxes when they head home.
- Staging Environments: These are typically used for final checks before a release. They only need to run when active testing is happening.
- QA and Testing Rigs: Whether it's automated test suites or manual QA, these activities happen on a schedule. There's no reason for those resources to be burning cash outside those windows.
Adopting Modern Cost-Efficient Architectures
While rightsizing and scheduling are about optimizing what you already have, adopting modern architectures is about redesigning your applications to be efficient from the ground up. Technologies like serverless and containers are transforming how we think about cost because they are built to eliminate idle waste by design.
-
Serverless platforms, like AWS Lambda or Azure Functions, run your code in response to specific triggers. You are billed only for the exact compute time your code uses, right down to the millisecond. This completely gets rid of the cost of servers sitting around waiting for something to do, making it perfect for workloads with spiky or unpredictable traffic.
-
Containers, managed by orchestrators like Kubernetes, offer a different flavor of efficiency. They let you pack your applications more densely onto virtual machines, which dramatically improves how well you're using your resources. This "bin packing" approach means you get more work done with fewer servers.
Making these architectural shifts isn't a walk in the park. It often requires a bigger upfront investment in new skills and the time to refactor applications. But the long-term payoff can be huge, leading to lower infrastructure costs and a more scalable, resilient system.
To see how these strategies compare in terms of effort and reward, have a look at this table.
Comparing Proactive Cost Control Strategies
| Strategy | Implementation Effort | Potential Savings | Best For |
|---|---|---|---|
| Rightsizing | Low to Medium | 10-40% | Quick wins on oversized resources and ensuring stable performance. |
| Scheduling | Low | 40-75% | Non-production environments (dev, test, staging) with predictable usage patterns. |
| Modern Architectures | High | 30-80%+ | New applications or major redesigns where long-term efficiency is a top priority. |
Each strategy has its place. Starting with scheduling and rightsizing can give you immediate results, while planning for architectural modernization sets you up for sustained savings down the road.
Recent industry data shows just how much money is being left on the table. A 2025 report found that 60% of companies still have idle network resources, and an incredible 90% could move workloads to cheaper compute options. The same study found that businesses that embraced serverless and containerized workloads cut their infrastructure costs by 35%. You can explore more cloud computing statistics from the full report to see just how big the opportunity is.
Using Automation and AI for Smarter Savings
Let's be honest: trying to manually keep your cloud spending in check is a losing battle. In an environment where resources pop up and disappear daily, relying on once-a-month reviews is like trying to catch rain in a thimble. By the time you spot a problem, the money is long gone.
This is where automation and artificial intelligence (AI) completely change the game. They shift your strategy from a reactive, after-the-fact chore into an intelligent, proactive system. These tools are the only way to scale your cost optimization efforts, moving you beyond tedious manual cleanups to a state of continuous, real-time savings.
Instead of hoping an engineer remembers to shut down a test server, an automated script can do it every single evening without fail. This doesn't just cut costs, it eliminates human error and frees up your valuable engineering talent to focus on building great products, not babysitting infrastructure.
Automating Routine Cost Control Tasks
The easiest place to start is by automating the basics: scheduling and cleanup. These tasks are repetitive, rule-based, and perfect candidates for automation. Think of it as putting your cost control on autopilot.
You can set up automated policies that tackle the most common sources of waste, ensuring your environment stays lean without someone constantly watching over it. This creates a safety net that stops cost spikes before they ever have a chance to blow up your bill.
Here are a few high-impact examples:
- Automated Scheduling: Use scripts or dedicated tools like CLOUD TOGGLE to automatically power down non-production environments (like dev, test, and QA) outside of business hours. This one simple action can slash the costs of those resources by over 70%.
- Idle Resource Termination: Create policies that automatically find and terminate idle resources. For example, a script can hunt down and delete unattached storage volumes older than 30 days or shut down virtual machines with less than 5% CPU usage for a week.
- Enforcing Tagging Policies: Automation is a fantastic governance tool. You can set up a rule that automatically quarantines or even terminates any new resource launched without the proper project or owner tags. This makes sure every dollar of spending is accounted for from the start.
Leveraging AI for Advanced Optimization
While basic automation handles the predictable stuff, AI takes your cloud cost optimization to a whole new level. AI-powered platforms can analyze massive, complex datasets to uncover savings opportunities that are nearly impossible for a human to spot.
These tools don't just tell you what happened last month. They provide predictive and prescriptive recommendations, actively guiding you toward smarter decisions.
AI-driven cost management moves beyond simple monitoring to predictive analytics. Industry reports show that organizations using these advanced tools have achieved a 20% reduction in unexpected cloud bill spikes by identifying anomalies before they become major problems.
AI shines when it comes to complex, data-heavy analysis. It can process millions of data points on performance metrics, pricing models, and workload patterns to offer highly specific, actionable advice that you can trust.
AI-Powered Recommendations You Can Act On
- Intelligent Rightsizing: AI algorithms dig into historical utilization data to recommend the perfect instance type and size for each workload. They can confidently suggest downsizing an overprovisioned server or even recommend switching to a different instance family (like moving to ARM-based Graviton processors) for a better price-performance ratio.
- Savings Plan and Reserved Instance Analysis: Figuring out the right commitment-based discount is a complicated financial puzzle. AI tools analyze your usage patterns to recommend the optimal purchase of Savings Plans or Reserved Instances, maximizing your discounts without the risk of overcommitting.
- Anomaly Detection: AI acts as a 24/7 watchdog for your spending. It constantly monitors your cost patterns and flags any unusual activity in real-time. If a developer accidentally launches a massive, expensive GPU instance for a small task, the system can alert you immediately, preventing a multi-thousand-dollar mistake.
Building a FinOps Culture for Cost Accountability

Let's be honest: true, sustainable cloud cost optimisation isn't just about finding the right tools or writing clever scripts. It’s a cultural shift. Without shared accountability, even the best automation will eventually hit a wall. This is where FinOps comes into play, building a much-needed bridge between your tech, finance, and business teams.
So what is FinOps? Think of it as the practice of bringing financial discipline to the cloud's flexible, variable spending model. It’s teamwork on a grand scale, getting everyone on the same page with a single goal: get the most business value out of every dollar spent in the cloud. It pulls cost management out of the IT silo and makes it a shared responsibility across the entire company.
This approach is all about collaboration and ownership. Instead of the finance team reacting to a massive bill at the end of the month, they work alongside engineers to understand why the money is being spent. This gives engineering teams the freedom to innovate while also making them aware of the real-world cost of their decisions.
The Core Principles of FinOps
A successful FinOps culture doesn't just happen. It's guided by a few core principles that change how teams think about and manage cloud spending. These principles create a framework for making smarter, more efficient decisions together.
The main pillars of this practice include:
- Collaboration is Key: Teams have to work together. Engineers, finance pros, and product managers must unite to make smart trade-offs between speed, cost, and quality.
- Business Value Drives Decisions: Every decision should be measured against the business value it delivers. The goal isn't just to be cheaper; it's to be more efficient with every dollar.
- Everyone Takes Ownership: When engineers can see the real-time cost of the resources they deploy, they are naturally motivated to build more efficiently.
- Centralized Governance: A central team provides best practices, sets budgets, and manages big-ticket items like commitment-based discounts, but day-to-day decision-making stays with the teams on the ground.
At its heart, FinOps is about having a data-driven conversation about cost and value. It treats cost as a critical metric, right alongside performance and reliability, without slowing down the innovation the cloud is supposed to deliver.
Visibility and Allocation: The Foundation of Accountability
You can't manage what you can't see. The very first step in building a FinOps culture is getting total visibility into your cloud spending. This means knowing exactly which team, project, or feature is responsible for every single line item on your bill. Without this, accountability is just a pipe dream.
Robust tagging is the bedrock of this visibility. A consistent and enforced tagging strategy lets you categorize every resource, turning a confusing invoice into a clear report that points costs to the right owners. This data can then feed into "showback" models, where costs are shown to the teams that incurred them, creating awareness and encouraging cost-conscious behavior.
Unfortunately, many organizations are still flying blind. A recent survey found that while 67% of CIOs rank cloud cost optimization as a top priority, only 30% of organizations know exactly where their budget is going. This problem only gets worse in larger companies. To fight this, 39% of executives now use unit economics, breaking down costs by customer or feature, to connect spending directly to business outcomes. Still, a staggering 78% of companies find cost variances too late, proving just how urgent the need for real-time visibility is. You can find more insights in these cloud computing statistics on cloudzero.com.
Ultimately, a strong FinOps culture empowers your teams. It gives engineers the data they need to make cost-aware architectural decisions from day one. It gives finance the predictability they need for accurate forecasting. And it aligns everyone on the shared goal of building an efficient, scalable, and profitable cloud operation. When finance and technology teams speak the same language, you can start asking smarter cloud finance questions that drive real business value.
Common Cloud Cost Optimisation Questions
Digging into cloud cost optimisation always stirs up a few questions. Whether you're just starting out or trying to tighten up an existing strategy, getting straight, practical answers is what matters. Let's tackle some of the most common questions to help you clear those hurdles and build a more efficient cloud setup.
The idea is to get away from reactive, panicked cleanups and move toward a proactive culture where financial accountability is just part of the process. This way, you can be sure you're squeezing the most value out of every dollar you put into the cloud.
What Is the Best First Step for Cloud Cost Optimisation?
The single most powerful first step is always visibility. It's simple: you can't optimise what you can't see.
Start by rolling out a mandatory, consistent tagging strategy. Every single resource needs to be categorised by its owner, be it a project, team, application, or environment. This one action immediately shines a light on exactly where your money is going, turning a messy, confusing bill into a report you can actually use.
Once you have that clarity, you can go after the "low-hanging fruit" by finding and killing off idle or completely unnecessary resources. These are the assets that deliver zero business value but keep quietly adding to your monthly bill.
Here are the top culprits to hunt down first:
- Unattached Storage Volumes: These are often the ghosts of terminated virtual machines, left behind to silently drain your budget every month.
- Old Snapshots and Backups: Take a hard look at your data retention policies. It's time to delete any snapshots that are no longer needed for compliance or recovery.
- Idle Virtual Machines: Look for servers running 24/7 that are only really needed during business hours, especially in your dev and test environments.
Nailing these first few steps delivers quick, measurable wins. Just as importantly, those early successes build momentum and get people on board for the bigger optimisation push, making it much easier to tackle more complex strategies down the line.
Do I Need a Special Tool to Optimise My Cloud Costs?
You can absolutely get started with the native tools your cloud provider offers, like AWS Cost Explorer or Azure Cost Management. For a small team working in a single cloud, these tools are a decent starting point for understanding your spend and spotting basic savings. They're a great entry point.
But as your cloud footprint grows, gets more complex, or spans multiple providers, a specialised third-party platform becomes pretty much essential. These dedicated tools bring some serious advantages to the table that the native options just can't match.
A dedicated cloud cost management platform moves beyond basic reporting to provide continuous, automated optimisation. It helps you scale your savings efforts in ways that are simply not possible with manual analysis or native tools alone.
Here’s what a specialised platform gives you:
- Superior Multi-Cloud Visibility: They offer a single dashboard to see and manage costs across AWS, Azure, Google Cloud, and more. Native tools are, by design, walled off.
- AI-Driven Recommendations: The best platforms use AI to sift through your usage data and serve up highly accurate recommendations for rightsizing, buying Reserved Instances, or adopting Savings Plans.
- Automated Cost-Saving Actions: This is the biggest win. These tools can automatically shut down idle resources, enforce your tagging rules, and handle other cost-saving tasks without anyone lifting a finger.
So, while native tools are a fine place to begin, a dedicated platform is what you'll need to achieve effective, continuous optimisation as you scale.
How Do I Save Money Without Hurting Performance?
This is the central puzzle that a mature FinOps practice is built to solve. The goal isn't just about slashing costs; it's about maximising the business value you get from every dollar spent in the cloud. Finding that balance requires tight, ongoing collaboration between your finance, engineering, and product teams. The conversation has to shift from pure cost-cutting to efficiency.
Engineers need the freedom to innovate and the resources to keep things fast and reliable. But they also need access to real-time cost data to see the financial impact of their architectural decisions. When cost becomes a visible metric right alongside performance, engineers are empowered to build more efficiently from the get-go.
Your optimisation efforts should zero in on rightsizing, making sure every resource perfectly matches its performance needs without wasteful overprovisioning. This isn't guesswork; it's about analysing historical performance data to make smart decisions. By building a culture where cost is a shared responsibility, you can cut waste without ever compromising the performance and availability your customers rely on.
Ready to stop paying for idle cloud resources? CLOUD TOGGLE makes it easy to automate server schedules, cutting costs by up to 70% on non-production environments with just a few clicks. Start your free 30-day trial and see how much you can save at https://cloudtoggle.com.



