Spot pricing is a way to buy unused cloud computing capacity from providers like AWS, Azure, and Google for a fraction of the regular cost. Think of it like an airline selling its last few empty seats at a massive discount just before takeoff. You get an incredible deal, but there's a catch: the provider can reclaim the resource with very little warning.
Understanding the Basics of Spot Pricing
At its core, spot pricing is a market-based model for cloud resources. Cloud providers like Amazon, Microsoft, and Google operate massive data centers with immense computing power. Not all of this power is used at once, leaving them with spare capacity.
Instead of letting these powerful servers sit idle, they offer them at steep discounts.

This creates a win-win scenario. You get access to powerful computing resources for tasks like data analysis, batch processing, or development environments at a low cost. The cloud provider, in turn, generates revenue from hardware that would otherwise be unused. The price for these resources, known as the spot price, fluctuates based on real-time supply and demand.
The Core Trade-Off: Savings vs. Availability
The fundamental concept to grasp is the trade-off between cost and reliability. You can achieve dramatic savings, but you sacrifice the guarantee of uninterrupted service.
The central bargain of spot pricing is simple: You gain access to compute power for up to 90% off standard rates, but you must be prepared for the possibility of your instances being terminated with as little as a 30-second notice.
This dynamic makes spot instances perfect for workloads that can tolerate interruptions. For example, if a data processing job is stopped, it can simply be restarted on another spot instance when one becomes available.
To get a handle on the basics, the table below breaks down the key concepts of spot pricing.
Spot Pricing Key Concepts at a Glance
| Concept | Description |
|---|---|
| Spare Capacity | Providers sell their unused, idle computing resources. |
| Market-Driven Price | The cost fluctuates based on the current supply and demand. |
| Massive Discounts | Savings can reach up to 90% compared to on-demand prices. |
| No Guarantees | Instances can be reclaimed by the provider with short notice. |
| Best for Fault-Tolerant Workloads | Ideal for tasks that can be stopped and restarted without issue. |
Understanding these core ideas is the first step to figuring out if spot instances are a good fit for your needs.
Spot pricing is an auction-based model where providers offer spare capacity at massive discounts, often up to 90% off on-demand rates. This makes it a game-changer for cost-conscious businesses managing their cloud environments. To gain a broader understanding of overall cloud spending and other methods for reducing expenses, consider exploring these essential cloud cost optimization strategies.
How Major Cloud Providers Handle Spot Pricing
While the core idea behind spot pricing is the same everywhere, the big three cloud providers, Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), each have their own unique spin on it. They all offer access to their spare compute capacity at a steep discount, but the mechanics, terminology, and trade-offs are different.
Understanding these differences is key. Each provider strikes a different balance between savings, how they handle interruptions, and the pricing models they use. This all comes down to their internal strategies for managing that spare capacity, so let's dive into how each one works.
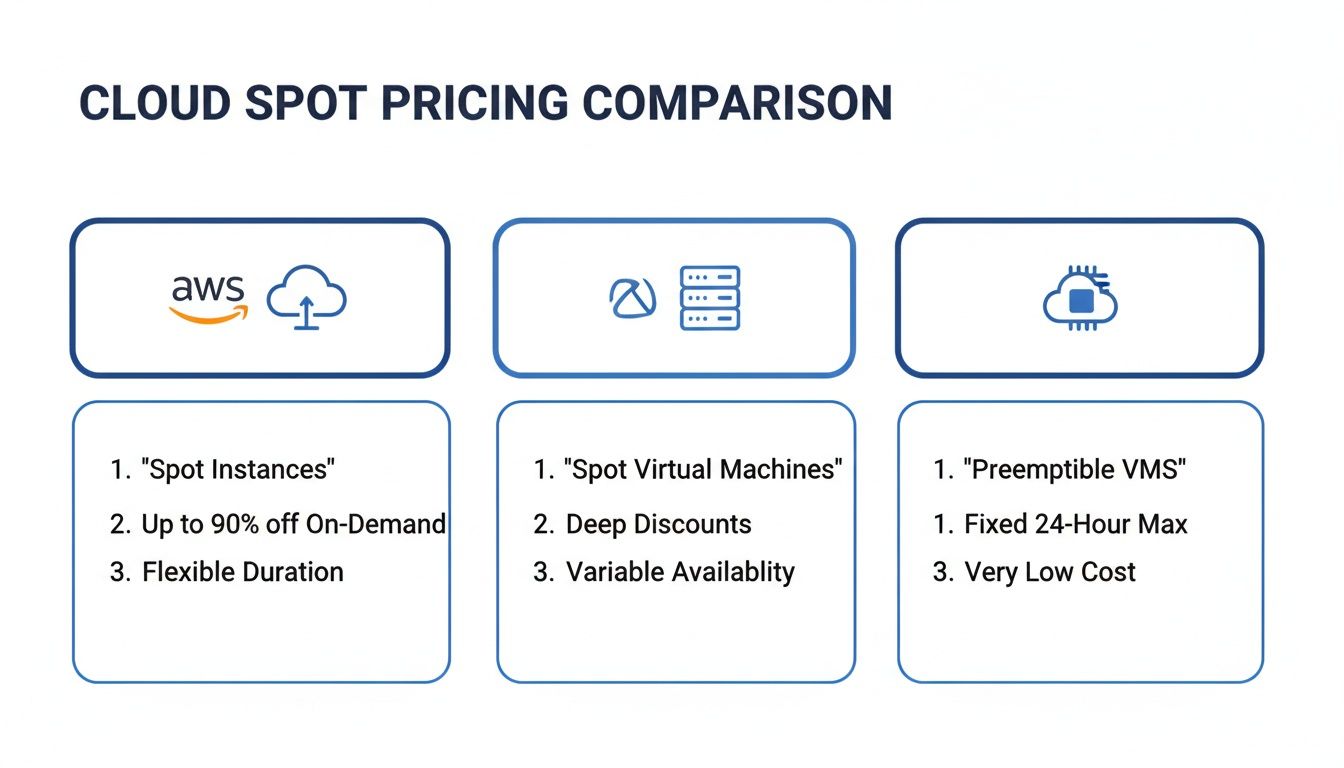
Amazon Web Services (AWS) Spot Instances
AWS was the pioneer here, and their Spot Instances still reflect that market-based origin. The price for an AWS Spot Instance isn't fixed; it moves up and down based on the long-term supply and demand for spare Amazon EC2 capacity. You can set a maximum price you're willing to pay, and your instance will keep running as long as the current spot price stays below your bid.
This approach gives AWS a ton of flexibility, but it also means you might see some price volatility. The biggest advantage with AWS is the warning time: you get a full two-minute notice before an instance is taken back. That might not sound like much, but in the world of cloud computing, it's a generous amount of time for your application to save its state, finish up a task, or hand off work gracefully before shutting down.
Azure Spot Virtual Machines
Microsoft’s offering is called Azure Spot Virtual Machines (VMs). They give you a bit more choice in how you pay. Like AWS, you can set a price cap you're not willing to exceed. But you can also just opt to pay whatever the current spot price is, which is a simpler way to go if you're less concerned about hitting a specific price ceiling.
Azure has a really useful feature called Azure VM Scale Sets, which lets you manage a whole fleet of identical VMs as a single unit. When you use Scale Sets with Spot VMs, Azure can automatically try to deploy a new instance if one gets evicted, helping you maintain the capacity you need and making your application more resilient.
The trade-off? Azure only gives you a 30-second notice before reclaiming a Spot VM. This means your shutdown scripts and state-saving processes need to be incredibly fast and efficient.
Google Cloud Platform (GCP) Spot VMs
Google Cloud took a different path with their Spot VMs (which evolved from their old "Preemptible VMs"). Instead of a dynamic, market-driven price like AWS, GCP offers a much simpler model: a massive, predictable discount of 60-91% off the standard on-demand price. This takes all the guesswork out of bidding and budgeting.
That simplicity is great, but it comes at a price. Just like Azure, GCP gives you a very short 30-second warning before an instance is terminated. This makes GCP Spot VMs a perfect fit for workloads that are highly fault-tolerant and stateless, things that can be stopped and started on a dime without causing any major issues. You can dive deeper into how these models stack up in our complete guide on Google Cloud prices.
It's amazing to think that this all started when AWS launched Spot Instances back on December 15, 2010. That move completely changed cloud economics by unlocking huge discounts on spare capacity, a model now followed by all its major competitors. For more on this, check out this excellent post on the breakdown of cloud computing costs on sedai.io.
Comparing Spot Offerings Across AWS, Azure, and GCP
To make it easier to see the differences at a glance, we've put together a simple comparison table. This breaks down the key features, interruption notices, and pricing models for each of the big three providers.
| Feature | AWS Spot Instances | Azure Spot VMs | GCP Spot VMs |
|---|---|---|---|
| Pricing Model | Dynamic, market-based price that fluctuates with supply and demand. | User can set a max price or pay the current spot price. | Fixed, predictable discount of 60-91% off on-demand rates. |
| Interruption Notice | 2 minutes | 30 seconds | 30 seconds |
| Interruption Cause | Spot price exceeds your max price or capacity is needed by AWS. | Azure needs the capacity back. | Google Cloud needs the capacity for other tasks. |
| Best For | Workloads that benefit from a longer warning time to save state. | Flexible workloads, especially when managed with VM Scale Sets. | Highly fault-tolerant, stateless, or short-lived batch jobs. |
As you can see, there's no single "best" option; it all depends on your workload's specific needs. If your application needs a bit more time to wrap things up, AWS is the clear winner. If you value predictable costs and your jobs are built to handle sudden interruptions, GCP's simple discount model is incredibly attractive. Azure sits somewhere in the middle, offering a good balance of features, especially for those already deep in the Microsoft ecosystem.
The Massive Reward and The Inherent Risk
Spot pricing works on a simple, powerful principle: high reward comes with high risk. The reward side is incredible, we’re talking about cost savings that can completely change the economics of a project, often hitting up to 90% compared to standard on-demand rates.
This isn't some minor discount. Imagine a complex data processing job that would normally cost $100 to run on a typical on-demand server. Using a spot instance for the exact same task, that cost could plummet to as little as $10. For startups, researchers, or any company running large-scale batch jobs, that's a game-changer. It unlocks more experimentation, faster data analysis, and the ability to scale up without obliterating the budget.
The Inherent Risk of Interruption
But here's the catch that balances out that massive reward: interruption. When you use a spot instance, you're essentially borrowing a resource that the cloud provider can take back at any moment. Think of it like running a pop-up shop in a building where the landlord can evict you with almost no notice if a full-paying tenant shows up.
This isn't a "maybe" scenario; it's a "when." When the cloud provider needs that capacity back, your instance will be terminated. Depending on the provider, you might get a two-minute warning or as little as 30 seconds to save your work and shut down. For any workload not built to handle sudden stops, this can mean lost data and wasted progress. Getting your head around this dynamic is the key to using spot pricing effectively.
This visual summary breaks down the key differences in how the major cloud providers handle their spot offerings.
The main takeaway? Each platform strikes a slightly different balance between savings, stability, and how much of a heads-up you get before an interruption.
Balancing Cost Savings and Availability
Deciding to use spot pricing boils down to a hard look at your specific workload. The people who win with spot instances are the ones who don't just accept the possibility of interruptions, they design their systems for it. They build applications that are fault-tolerant, stateless, or can checkpoint their progress frequently.
The core strategy for spot pricing is not to avoid interruptions, but to plan for them. By treating terminations as a normal part of operations, you can harness immense cost savings without sacrificing the reliability of your overall system.
This proactive approach turns the biggest risk of spot pricing into just another operational detail to manage. It really comes down to this trade-off:
- The Reward: You get access to powerful computing resources for a tiny fraction of the standard cost. This makes large-scale processing and experimentation possible when it would otherwise be too expensive.
- The Risk: Your instance can be shut down with minimal warning. This means your workloads absolutely must be fault-tolerant and able to save their state or restart without losing data.
Ultimately, mastering spot pricing means accepting this risk and engineering your applications to thrive within these constraints. Do that, and you unlock enormous value.
Finding the Perfect Workloads for Spot Pricing
Not every application can just be thrown onto a spot instance and be expected to work. The secret to making spot pricing a success is picking the right kind of job, the kind that can handle being unexpectedly interrupted.
The magic word here is fault-tolerant. You need workloads that can be paused or stopped and then pick back up again without losing data or derailing the entire process. Think of a 3D animation studio rendering a movie. Each frame is a tiny, independent job. If one server gets reclaimed mid-render, no big deal. The system just hands that frame off to another machine. The final movie is perfectly fine because the whole operation wasn't built on any single server staying online.
Big Data and High Performance Computing
Large-scale data processing is practically tailor-made for spot pricing. Frameworks like Apache Spark and Hadoop are built from the ground up to spread work across a massive fleet of machines. They already assume individual nodes can and will fail, which makes them a perfect fit for the unpredictable spot market.
It's the same story with scientific and high performance computing (HPC). These jobs often run huge, parallel calculations that can be checkpointed, meaning they periodically save their progress. If a spot instance vanishes, the job can simply resume from its last saved state instead of starting over from scratch. This minimizes wasted time and money.
- Big Data Analysis: Chewing through terabytes of logs or running complex analytics where any failed task can just be retried.
- Scientific Modeling: Think genomic sequencing or climate simulations that are easily broken down into smaller, independent chunks of work.
- Media Rendering and Transcoding: This is a classic. Rendering animations or converting massive video files are ideal batch jobs for cheap, interruptible compute power.
Development and Continuous Integration Pipelines
One of the best and safest places to use spot pricing is in your non-production environments. Your development servers, testing environments, and CI/CD pipelines just don't need the same rock-solid 99.99% uptime as your live, customer-facing website.
An interruption in a CI/CD pipeline might delay a software build by a few minutes. That's usually a tiny price to pay for saving up to 90% on your compute bill. The job just kicks off again when a new spot instance is available.
These environments are a slam dunk for spot instances because they're temporary by design. A developer's test server can be spun up in minutes, and a CI job is meant to be short-lived anyway. Using spot instances here slashes the cost of infrastructure that would otherwise be sitting idle most of the time.
Stateless and Containerized Applications
Stateless applications are another perfect match. These apps don't store any session-specific data on the local server. Every request from a user is treated like a brand-new interaction, so it doesn't matter which machine handles it.
This design makes them incredibly resilient. If a spot instance running a web server is terminated, the load balancer just stops sending it traffic and directs new requests to the other healthy instances in the pool. For the end-user, it's completely seamless.
Workloads managed by container orchestrators like Kubernetes are especially good at this. The system is designed to automatically notice when a container (or "pod") dies and will reschedule it onto a new, healthy node. This approach turns the "risk" of spot pricing into just another manageable, automated operational task.
How to Manage Spot Instance Interruptions

Here's the secret to winning with spot pricing: you don't try to avoid interruptions. You build a system that expects them.
When you treat terminations as a normal, everyday part of operations, you turn the biggest risk into just another manageable detail. This shift in mindset is what lets you capture those massive savings without putting your whole application at risk.
The core of this strategy is weaving resilience right into your architecture. Your applications need to be stateless, loosely coupled, and fault-tolerant. In simple terms, this means one server can vanish into thin air without taking the entire system down with it.
Implement Checkpointing for Long-Running Tasks
For any job that runs longer than a few minutes, checkpointing is your best friend. It’s a simple but powerful technique where you periodically save your application's progress to a durable, separate storage service like Amazon S3 or Azure Blob Storage. Think of it as an autosave feature in a video game.
When a spot instance gets its two-minute warning, its last act is to save a final checkpoint. A brand-new spot instance can then spin up, load that last save file, and pick up the job exactly where the old one left off. This simple process prevents you from losing hours of computation, making spot instances a totally viable option for heavy-duty data processing or scientific modeling.
Use Instance Groups for Automatic Capacity Management
Managing individual spot instances is a headache waiting to happen. A much smarter way is to use instance groups. These services, offered by all the major cloud providers, handle the dirty work of requesting, maintaining, and replacing instances to keep your desired capacity online. We cover how to get the most out of these tools in our detailed guide on AWS EC2 spot instances.
These groups are your key to building a tough and diversified fleet of servers.
- AWS Spot Fleet: Lets you request capacity across multiple instance types, sizes, and even different Availability Zones in a single go. This massively increases your odds of grabbing available spot capacity.
- Azure VM Scale Sets: Allows you to manage a huge pool of identical VMs as one unit, automatically swapping out any spot instances that Azure reclaims.
- GCP Managed Instance Groups (MIGs): Delivers similar functionality, "healing" the group by automatically recreating any instances that get terminated or deleted.
By spreading your instance requests across different types and availability zones, you dramatically soften the blow of a price spike or capacity shortage in any single spot market. Diversification isn't just for investing; it's a critical strategy for a stable cloud environment.
These automated fleets are the foundation of any solid spot pricing strategy. They handle the grunt work of finding and replacing instances, letting your applications cruise along with minimal disruption, even if individual servers are popping in and out of existence. This architectural leap, from fragile single servers to resilient fleets, is what makes spot pricing such a powerful and reliable way to slash your cloud bill.
Combining Spot Pricing with Scheduled Shutdowns
While spot pricing is a fantastic tool for cutting costs on flexible workloads, it's not the only trick in the book. A truly smart cloud cost strategy combines the reactive savings of spot instances with the proactive approach of scheduled shutdowns.
Think of it this way: these two methods are different tools for different jobs. Spot pricing is your go-to for unpredictable, fault-tolerant tasks like data processing or batch jobs. Scheduled shutdowns, on the other hand, are perfect for the predictable rhythm of non-production resources, like the development and staging servers that only need to be running during business hours.
Proactive vs. Reactive Savings
By using both, you cover all your bases. Spot pricing reacts to spare cloud capacity, grabbing cheap compute for jobs that can handle interruptions. Meanwhile, a scheduler proactively powers down idle on-demand resources based on a simple, predictable timetable. This creates a much more complete cost-saving plan.
When you combine these approaches, you capture savings across the full spectrum of your cloud usage, not just one part of it. One handles the unpredictable jobs reactively, while the other manages predictable resources proactively.
This hybrid model maximizes your efficiency. For instance, you could run your CI/CD pipeline on spot instances to get cheap, fast builds. At the same time, you can use a tool like CLOUD TOGGLE to automatically shut down your team's development servers every night and weekend. Our guide on how to schedule AWS instances walks through exactly how to set this up.
A Multi-Layered Approach to Cloud Costs
This combined strategy really pays off. On their own, spot instances can deliver incredible savings of 50-90% off standard rates. When blended with other models, this often leads to 30-50% total reductions in your cloud bill.
When you start mixing Reserved Instances for your stable workloads, spot instances for the flexible ones, and schedulers to power off everything that’s idle, you can see immediate 20-40% savings without any complex re-engineering. You can explore more about these blended cloud cost optimization models on northflank.com.
Ultimately, spot pricing and scheduled shutdowns aren't competing ideas, they’re complementary tactics. Using both ensures you're not leaving money on the table. This two-pronged attack on waste is the key to turning your cloud infrastructure into a highly efficient operation and achieving deep, sustainable savings.
Got Questions About Spot Pricing? We've Got Answers.
We've covered a lot of ground, but you probably still have a few questions. Here are some of the most common ones we hear.
Can I Set a Maximum Price for a Spot Instance?
Yes, you absolutely can. On a platform like AWS, you can specify the maximum price you're willing to pay per hour. Your instance will only run as long as the live spot price stays below your limit.
If the market price suddenly spikes past what you’ve set, your instance gets terminated. This gives you a powerful lever to control your spending and shield your budget from unexpected price jumps.
What Happens to My Data When a Spot Instance Is Terminated?
This is a critical point: when a spot instance is terminated, any data stored on its local drive is gone for good. It's wiped clean.
To avoid losing your work, you have to save everything to persistent external storage, like Amazon EBS or Azure Disk Storage. Making it a habit to regularly save your application's state, a process called checkpointing, is non-negotiable if you want your workloads to be resilient.
Is Spot Pricing Safe for Production Websites?
Generally, no. You wouldn't want to run your main customer-facing website or a critical database on something that could vanish with only a two-minute warning. The risk of interruption is just too high for anything that demands constant uptime.
However, spot pricing can be a fantastic fit for certain parts of a production system that are designed to be fault-tolerant. For instance, imagine a fleet of stateless web servers sitting behind a load balancer. If a few of those servers get terminated, the load balancer simply reroutes traffic to the remaining ones. Your users would never even notice.
Ready to slash your cloud costs without the risks of spot instances for your predictable workloads? CLOUD TOGGLE helps you save by automatically scheduling your non-production servers to turn off when they are not needed. Start your free 30-day trial at cloudtoggle.com and see how much you can save.



