A lot of teams hit the same decision point at the same time. The service is designed, the API contract is clean, the backlog is full, and the code is close to ready. Then the deployment question shows up: should this run on Lambda or on Fargate?
That choice looks simple when you only compare pricing pages or feature grids. In production, it rarely is. The wrong fit doesn't just raise your AWS bill. It changes how your team debugs incidents, handles state, manages startup latency, and explains architecture decisions six months later when the workload no longer resembles the original estimate.
The practical version of fargate vs lambda is not "containers versus functions." It's operational shape versus workload shape. If those two don't match, you pay for it in hidden complexity.
The Serverless Crossroads Choosing Your Path
A team lead usually doesn't ask about Fargate and Lambda in the abstract. The question comes from a service.
Maybe it's a new ingestion pipeline that wakes up when files land in S3. Maybe it's a customer-facing API that has quiet mornings and busy afternoons. Maybe it's a worker service that started as "just a job runner" and now needs retries, custom binaries, persistent connections, and scheduled execution.
At that point, the architecture discussion gets messy fast. Lambda feels attractive because it removes more infrastructure decisions. Fargate feels safer because it preserves the container workflow many teams already know. Both are serverless, but they create very different operational habits.
I usually frame the choice around one question: what are you trying to avoid? If the team wants to avoid host management and keep container packaging, Fargate often wins. If the team wants execution that appears only when events arrive, Lambda often wins.
That still isn't enough. You also need to think about what the workload becomes after launch. Services that look event-driven at first often grow state, background coordination, or dependency sprawl. Services that start in containers sometimes turn out to be narrow handlers that would be simpler as functions. A broader comparison like AWS Fargate vs. ECS vs. Lambda is useful when you're sorting out whether the core comparison is instance control, orchestration model, or ownership model.
Here's the practical reality. You are not choosing a cheaper runtime in isolation. You are choosing the failure modes, scaling behavior, and cost traps your team will live with.
| Dimension | AWS Lambda | AWS Fargate |
|---|---|---|
| Best fit | Event-driven, short-lived tasks | Containerized, longer-running services |
| Packaging model | Function deployment | Container image |
| Runtime style | Stateless invocation model | Persistent task model |
| Scaling pattern | Per request, automatic | Task-based, policy-driven |
| Startup profile | Fast when warm, variable on cold starts | Slower task startup, steadier once running |
| Cost shape | Strong for intermittent usage | Strong when containers need to stay active |
| Operational burden | Lower at small scope, can rise with complexity | Higher upfront than Lambda, often simpler for container-heavy teams |
Understanding the Core Concepts of Fargate and Lambda
A team usually feels this choice first in delivery, not architecture diagrams. One path says, "ship a handler and let AWS run it on demand." The other says, "ship a container and let AWS run the task without giving you servers to manage." That difference sounds small early on. It becomes expensive later if the runtime model fights the way the application behaves.
AWS Lambda is a function-as-a-service platform. You provide code, connect it to an event source, and AWS runs it per invocation. The operating model is built for discrete work triggered by requests, messages, schedules, or changes in other AWS services.
AWS Fargate is managed compute for containers through Amazon ECS or EKS. You still own the container image, process model, and task definition. AWS removes host management, but your team still thinks in services, tasks, deployments, and container lifecycle.
If your team is still sorting out whether the fundamental comparison involves instance control versus event-driven execution, this EC2 vs Lambda comparison for infrastructure ownership and runtime trade-offs helps frame the baseline.
Lambda starts with the unit of work
Lambda fits best when the application can be broken into small, independent executions. Code starts because something happened. It handles the event, writes state somewhere else if needed, and stops.
That model works well for:
- File and media processing triggered by object uploads
- Narrow API handlers with clear request and response boundaries
- Queue consumers that process messages independently
- Scheduled jobs and automations tied to AWS events
The hidden benefit is reduced infrastructure ownership. The hidden cost is that function boundaries become part of your application design. Once a system grows across many functions, teams spend more time on IAM scoping, deployment packaging, concurrency controls, retries, and observability stitching than they expected from the word "serverless."
Fargate starts with the application process
Fargate assumes your workload is better expressed as a containerized service or worker. You package the app with its runtime and dependencies, assign CPU and memory, and run it as a task under ECS or EKS.
That tends to fit:
- HTTP services that need a long-running process
- Background workers with custom dependencies or multi-process behavior
- Batch and data jobs that run longer or need more runtime control
- Container-first teams that already build, scan, and promote Docker images in CI/CD
The trade-off is straightforward. Fargate preserves application shape, which often lowers refactoring effort and avoids Lambda sprawl. It also brings more operational surface area than Lambda. You still deal with task sizing, image management, service rollout behavior, health checks, and cluster-level configuration through ECS or EKS.
The core concept gap is the ownership model
Both services remove server administration. They do not remove operational responsibility.
Lambda shifts more responsibility into application decomposition and event design. Fargate shifts more responsibility into container operations and service management. That distinction matters for total cost of ownership because the AWS bill is only part of the picture. The team also pays in deployment complexity, debugging time, local development friction, and how much architecture work is needed to make production behavior predictable.
This is why teams that look only at per-request pricing or per-vCPU pricing often make the wrong choice. The better question is simpler. Is this workload naturally a short-lived event handler, or is it an application process that happens to run on managed infrastructure?
Architectural and Operational Differences
The biggest gap between Lambda and Fargate isn't the runtime itself. It's the amount of architecture you need around the runtime to make a production system behave well.

Packaging changes how teams ship software
Lambda encourages narrow deployment units. That can be a benefit when a team wants isolated handlers with clear ownership. One function, one trigger, one job. It's a good shape for event-driven systems.
But small deployment units also create sprawl if the service boundary isn't disciplined. A simple backend can turn into many functions, each with its own IAM role, packaging concerns, environment variables, and monitoring setup.
Fargate takes the opposite approach. You ship a container image, which gives you more control over dependencies and runtime behavior. If your team already uses Docker in CI/CD, the path feels familiar. You package once and promote the same image through environments.
That familiarity matters. Teams often underestimate how much friction they avoid when they don't need to refactor application structure around function boundaries.
Stateless sounds simple until the application isn't
Lambda is stateless by design. That's elegant for event processing and awkward for systems that need continuity.
Most production applications need some form of persistence, session handling, connection reuse, cache coordination, or intermediate state. When Lambda runs those workloads, teams usually add external components such as DynamoDB or ElastiCache. According to Bacancy's analysis of Fargate vs Lambda, that architectural requirement can increase total system costs by 20-40% compared to Fargate's container-native state capabilities.
This is one of the most important TCO differences and one of the least discussed.
The direct cost matters, but the operational burden matters too. Every external state layer adds:
- More permissions to review and maintain
- More services to monitor and troubleshoot
- More latency paths between app logic and data
- More failure scenarios during deployments and incidents
Stateful needs don't just affect design. They affect on-call complexity.
Fargate isn't magically stateful in the sense of replacing durable storage, but it gives you a more natural runtime for applications that need longer-lived processes, open connections, and application-level continuity.
Networking and runtime control feel different in daily operations
Lambda works best when the runtime can stay light and the network interactions are straightforward. Once a function needs private networking, multiple downstream dependencies, and careful startup behavior, you start paying more attention to packaging size, initialization, and invocation patterns.
Fargate feels heavier upfront, but more predictable to teams that already think in service networking and task definitions. You know where the process runs, how it's packaged, and how resources are allocated per task. That can simplify operations for platform teams even if the service itself looks more complex on paper.
A helpful adjacent read on trade-offs in AWS compute models is this CloudToggle post on EC2 vs Lambda, especially if your team is still deciding how much infrastructure control it wants to retain.
Monitoring tells a different story on each platform
With Lambda, observability often starts at the invocation level. You care about event source behavior, execution duration, retry patterns, and downstream call performance. That works well when the business process is already event-oriented.
With Fargate, observability tends to look more like service operations. You watch task health, container logs, memory pressure, service deployment state, and task replacement behavior.
Neither model is better. They are different operating surfaces.
What usually works and what usually does not
Lambda works well when the code is narrow, stateless, and clearly triggered by events.
Lambda works poorly when the team is trying to force a long-lived service into function form just to stay "more serverless."
Fargate works well when the application already fits the container model and the team wants to preserve that shape without managing instances.
Fargate works poorly when the workload is tiny, sporadic, and would spend most of its life doing nothing inside a running container.
Comparing Scaling and Performance Under Load
A traffic spike is where the Fargate versus Lambda decision stops being theoretical. The team feels it in latency, retry volume, and the on-call load that follows.
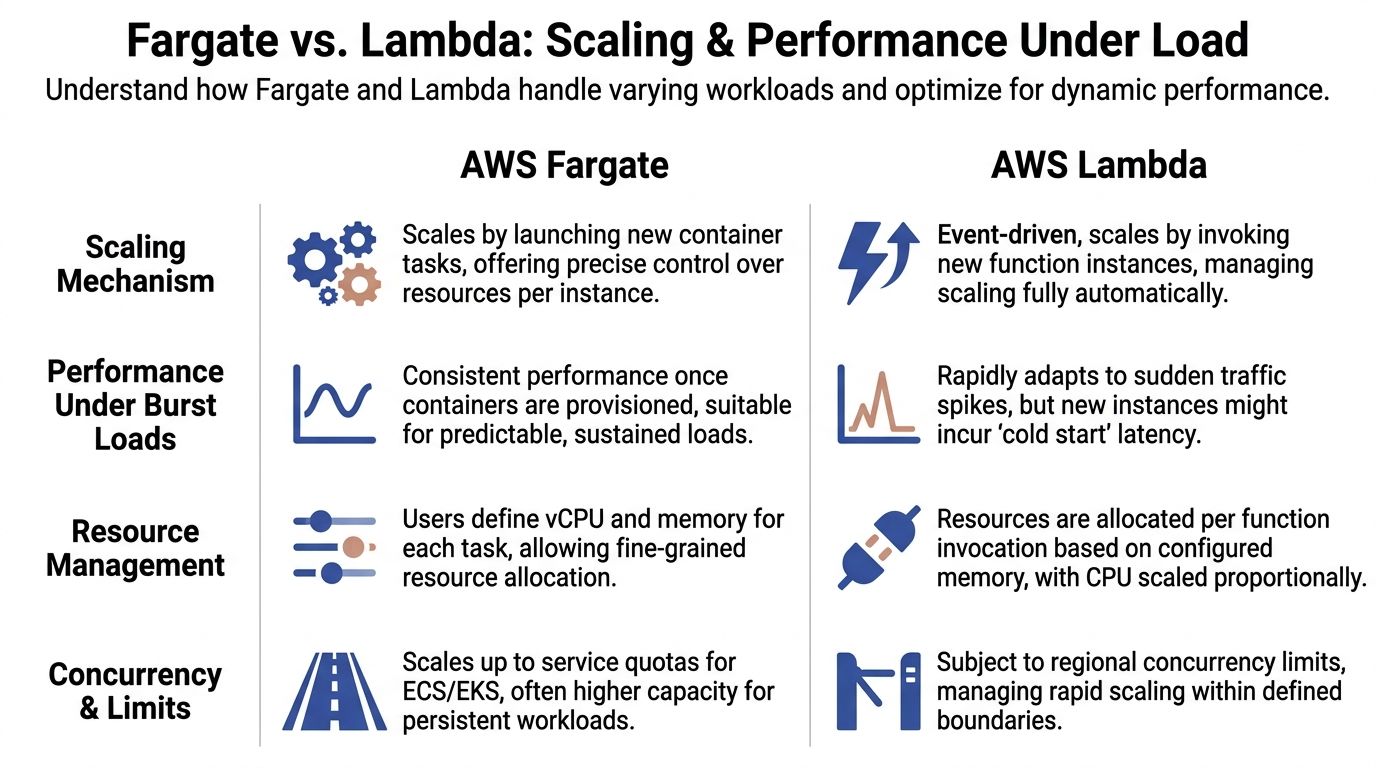
Lambda scales by creating more executions
Lambda responds to incoming events by starting more execution environments. For bursty traffic, that is often the fastest way to absorb demand without keeping spare capacity running all day.
The trade-off is less obvious on the pricing page. Fast scale-out can still create production friction. Cold starts, concurrency controls, downstream throttling, and retry storms all show up as operational work. If the service sits in front of a database, a queue consumer, or a rate-limited third-party API, Lambda can scale faster than the dependency behind it. At that point, the platform is doing its job, but your system is not.
Teams that do this well treat Lambda scaling as a full-path design problem, not just a function setting.
Fargate scales by adding container tasks
Fargate grows capacity by launching more tasks. That usually means slower scale-out than Lambda, but the runtime behavior is easier to reason about once tasks are up and healthy. For long-lived APIs, background workers, and services with steady request volume, that predictability can matter more than raw burst response.
The hidden cost is buffer capacity. To avoid slow scale-up during peaks, teams often keep extra tasks running, set more aggressive autoscaling thresholds, or provision larger tasks than average traffic requires. Those choices improve service stability, but they also raise the monthly baseline.
A useful companion read is how cloud scaling works. The important question is not whether a platform scales. It is how quickly it reaches useful capacity, and what you have to pay or operate in the meantime.
Performance under load is shaped by startup behavior and dependency limits
Cold starts get too much attention in isolation. They matter, but the production issue is variance.
Lambda can look excellent in test runs and still produce uneven latency during bursts, after idle periods, or during rapid concurrency growth. That variance affects user-facing APIs, but it also affects cost. Extra retries, duplicate work, more verbose logging during incident response, and defensive overprovisioning in adjacent services all add TCO that basic invocation estimates miss.
Fargate has a different profile. New capacity generally takes longer to arrive, but running tasks behave more like a conventional service. That tends to simplify load testing, capacity planning, and incident triage. For some teams, that operational predictability is worth more than shaving idle cost from the compute line item.
This is also where understanding cloud scalability helps. Scaling is not only about adding compute. It is about how the whole application behaves while demand is changing.
The practical decision under pressure
Use Lambda when demand is irregular, requests are independent, and the surrounding architecture can tolerate fast concurrency growth.
Use Fargate when the service needs steadier runtime behavior, longer-lived processes, or tighter control over how capacity comes online.
If the workload needs both patterns, split it. A common production design is Lambda for event intake and Fargate for the stateful or continuously running parts. That usually produces a cleaner operating model than forcing one platform to cover both jobs.
A Practical Breakdown of Cost Models and Pricing
The pricing pages make this look straightforward. Lambda charges per invocation and execution time. Fargate charges for allocated vCPU and memory while the task runs. Real bills are shaped by workload behavior, not by the headline billing unit.

Lambda is strongest when idle time dominates
Lambda's billing model is a strong fit when code runs only in response to demand. If an API receives uneven traffic, or a background task wakes up only when events arrive, Lambda avoids paying for waiting.
That sounds obvious, but it's the main reason many teams prefer it for new services with uncertain usage patterns. There is less penalty for being wrong about traffic early, as long as the service remains stateless and short-lived.
Fargate is easier to justify when service continuity matters
Fargate charges for provisioned task resources while those tasks are running. If your application needs a continuously available process, this can be the cleaner cost model because you're paying for an active service, not simulating one through repeated invocations and support services.
The mistake teams make is assuming that "serverless" always means "automatically cheaper." It doesn't. If the service needs to stay warm, maintain process-level continuity, or hold containerized dependencies all day, Fargate's model may be easier to control.
A practical way to estimate total cost
For architecture reviews, I usually break the estimate into three layers:
Direct compute cost
Lambda means invocation-driven execution cost. Fargate means task resource cost over time.Support architecture cost
Lambda often needs more surrounding services when the application requires state, session continuity, or specialized runtime behavior.Operational handling cost
This is the part finance teams rarely see. On-call overhead, deployment complexity, scaling surprises, and debugging time all belong in TCO.
If your team is working through broader patterns of elasticity and utilization, this primer on understanding cloud scalability is useful context before you estimate where a workload will sit on the idle-to-steady spectrum.
Where teams get the math wrong
They compare compute line items and stop there.
That approach misses the hidden costs already covered earlier in this article: cold-start overhead for Lambda in the wrong traffic profile, and the extra infrastructure needed when a supposedly stateless application turns out not to be stateless in production.
It also ignores one practical issue in Fargate environments. Containers that are "temporarily needed" often become persistent. Development services, internal tools, and off-hours batch runners can keep accruing spend because no one put hard schedules around them.
For teams evaluating that side of the equation, CloudToggle's breakdown of AWS Fargate pricing is worth reviewing alongside the official calculators.
A short visual explainer can help if you're walking teammates through the difference between pricing mechanics and operational spend.
The cheapest service on paper often becomes the most expensive one to operate when the workload shape doesn't match the runtime.
Common Use Cases and a Decision Matrix
By the time a team reaches this stage, the decision usually isn't philosophical anymore. It's workload-specific.
Event-driven processing
For upload processing, queue-triggered transformations, lightweight automations, and narrow data handlers, Lambda is usually the better fit.
The reason isn't just ease of use. The event boundary already exists. The runtime model follows the workload naturally.
Synchronous APIs
This one depends on the API shape.
If the API is thin, stateless, and maps cleanly to request handlers, Lambda can work very well. If the API starts pulling in heavy dependencies, longer startup logic, or more service continuity expectations, Fargate becomes easier to run without architecture contortions.
Background jobs and workers
For simple, discrete jobs, Lambda is attractive.
For workers that need custom binaries, longer processing windows, or stable application processes, Fargate is the safer operational choice. This is especially true when the worker starts life as a container already.
Long-running web services
Choose Fargate.
This is the case where teams often waste time trying to preserve a pure function model for something that is clearly a service. If the app wants to stay up, keep connections open, and behave like an application process, containers are the more natural fit.
Don't reward theoretical purity over operational fit. Teams maintain systems, not diagrams.
Hybrid patterns are often the best answer
Many strong AWS architectures use both.
Lambda handles ingestion, event fan-out, and utility automation. Fargate runs the API, worker tier, or service components that need runtime continuity. That split is often more practical than trying to force a single compute model across all jobs.
Fargate vs Lambda Decision Matrix
| Criterion | AWS Lambda | AWS Fargate | Best Choice For… |
|---|---|---|---|
| Execution duration | Best for short-lived work | Better for sustained and long-running tasks | Match the natural runtime length |
| Traffic pattern | Strong for bursty, event-driven demand | Strong for steadier service demand | Spiky events versus persistent services |
| Packaging approach | Function deployment model | Container image workflow | Team preference and existing toolchain |
| State handling | Better when state can stay external and minimal | Better when the app benefits from process continuity | Stateful application behavior |
| Startup behavior | Fast when warm, variable when cold | Slower to start, steadier once active | Latency-sensitive bursts versus stable runtime |
| Operational style | Fine-grained event operations | Service and container operations | Team skill set and platform maturity |
| Dependency complexity | Best with lean runtime needs | Best with custom runtime and container dependencies | Heavy libraries, tools, or custom images |
| Cost efficiency | Best when idle periods are common | Best when tasks need to remain active | Intermittent usage versus active service time |
| Migration flexibility | Good for decomposed handlers | Good for existing containerized apps | Greenfield functions versus Docker-based services |
A simple decision shortcut
Use Lambda if most of these are true:
- Events trigger the work
- The task is short-lived
- State can stay minimal
- You want the smallest operational surface
Use Fargate if most of these are true:
- You already have a container
- The service needs to stay alive
- Dependencies are complex
- The team wants predictable container operations
Practical Cost Optimization and Migration Guidance
A team picks Lambda for lower unit pricing, then adds provisioned concurrency, extra observability tools, retry handling, and more engineering time around deployment sprawl. Another team keeps a service on Fargate, leaves it running around the clock, and pays for idle capacity that nobody needed overnight. In both cases, the pricing page was only part of the story. Total cost of ownership comes from the runtime, the support services around it, and the amount of operational discipline the team can sustain.
How to keep Lambda efficient
Right-size memory using real execution data. Lambda pricing is tied to configured memory, and memory settings also affect CPU allocation, so the cheapest setting on paper is not always the cheapest setting per completed job.
Cold-start mitigation needs restraint. Provisioned concurrency can solve a latency problem, but broad use can turn an event-driven platform into a partly pre-paid one. Apply it only to functions with strict response-time requirements and consistent traffic patterns.
Keep function scope tight. Once a function starts pulling in heavy libraries, complex orchestration, and too many network calls, the runtime cost is no longer the only concern. Build time, test time, debugging effort, and deployment risk all go up. That is often the point where a containerized service is easier to operate, even if the raw invocation math still looks acceptable.
How to keep Fargate efficient
Treat runtime hours as a design choice. Fargate waste usually comes from services that stay up by habit, not because the workload needs continuous availability.
Smaller service boundaries help in two ways. They let the platform scale the expensive part of the system instead of the whole stack. They also make it practical to stop non-production tasks after hours, or run batch-style containers on a schedule instead of keeping them warm all day.
Image hygiene matters more than teams expect. Large images slow deployments, increase startup time, and create friction during incident response because every fix takes longer to roll out. Clean startup paths and conservative autoscaling settings also matter. Aggressive scaling can protect latency, but it can just as easily hide inefficient code behind more running tasks.
Migration advice that saves pain
The safest Fargate-to-Lambda migration starts by carving out one narrow path that already behaves like a function. Webhook receivers, file transforms, and isolated async jobs usually migrate well because they have a clear trigger, limited state, and a short execution window.
Lambda-to-Fargate migrations usually happen for operational reasons, not ideological ones. Common signals include:
- Dependency size is making builds, deploys, or cold starts painful
- The workload needs longer-lived processing or steady background activity
- State coordination is spreading across too many external services
- Troubleshooting is harder because execution is split across many small functions
That shift is often a sign of normal application growth. The better question is whether the current runtime still matches the operating model your team can support at production scale.
The optimization opportunity teams miss
Many cost reviews stop at compute pricing. That misses the bigger savings.
A workload can be "serverless" and still behave like persistent infrastructure once you add queues, logs, tracing, NAT, image scanning, alarms, and the engineering time to keep everything healthy. The same thing happens in Fargate when always-on tasks, oversized environments, and broad autoscaling policies stay in place long after the original traffic assumptions changed.
The practical framework is simple:
- Choose the runtime that fits the execution pattern
- Count the supporting services and operational work that come with that choice
- Shut off anything that does not need to run continuously
That third question is often the fastest way to improve cloud bills.
If your team wants to cut waste from idle cloud resources without giving broad cloud-account access to everyone, CLOUD TOGGLE is worth a look. It helps teams schedule power-off windows for idle servers and VMs, apply policy-based control across environments, and reduce spend from resources that native "always available" habits leave running far longer than necessary.



