Teams rarely decide to build a cloud center of excellence on a calm Tuesday afternoon. They get pushed there.
A few teams have already moved fast in AWS or Azure. Finance sees cloud invoices that don't map cleanly to products or departments. Security finds different IAM patterns in every account. Engineering wants faster provisioning, but every new workload triggers the same debates about naming, networking, logging, and who owns cost. Cloud adoption starts as freedom and turns into friction.
That pattern is common because cloud makes it easy to create resources and much harder to create consistent operating rules. One team tags carefully. Another doesn't. One environment follows approved network patterns. Another grows from a quick proof of concept that never got cleaned up. The result isn't just waste. It's hesitation. Teams slow down because nobody trusts the system.
A cloud center of excellence earns its place. Not as a committee that says no, but as the group that makes safe, repeatable cloud delivery possible. The shift toward structured cloud management is already well established. Approximately 75% of enterprises had implemented a CCoE by 2021, according to CloudQuery's overview of building effective cloud governance.
For SMBs and mid-market companies, the idea can sound bigger than it needs to be. It doesn't require a large enterprise bureaucracy. It requires a small group with authority, practical standards, and a clear mandate to improve security, cost control, and delivery speed. If your team is already dealing with the daily realities of misconfigurations, approval bottlenecks, or unclear ownership, a good grounding in MSP Pentesting's cloud security guide is a useful companion to that effort because it frames the kinds of risks a CCoE should reduce from the start.
Introduction From Cloud Chaos to Strategic Control
A cloud center of excellence works best when it's built around a simple promise. Teams should be able to move faster because the hard decisions have already been made once, documented, automated, and supported.
What the chaos usually looks like
In smaller companies, cloud governance often starts as tribal knowledge. The senior engineer knows which VPC pattern is acceptable. The platform lead knows which workloads can shut down after hours. Finance knows the bill is climbing, but not why. None of that scales.
Common symptoms show up quickly:
- Costs drift unnoticed: Idle compute, duplicate environments, and poor ownership make spend hard to challenge.
- Security varies by team: IAM, logging, encryption, and network rules get implemented differently across accounts.
- Delivery slows down: Engineers wait for decisions that should have been standardized months ago.
- Business ownership stays blurry: Product leaders want elasticity and speed, but don't have a clean view of what their workloads cost.
A strong CCoE doesn't centralize every decision. It centralizes the decisions that shouldn't be reinvented.
What strategic control actually means
Strategic control is not about adding reviews to every change. It's about defining a small number of high-value controls and making them easy to follow. That usually includes account structure, tagging rules, identity baselines, approved deployment patterns, logging standards, and budget ownership.
For practical teams, that's the turning point. Instead of asking, "Who approves this cloud setup?" you get to ask, "Does this setup match the standard?" That change matters because standards are scalable. Heroics aren't.
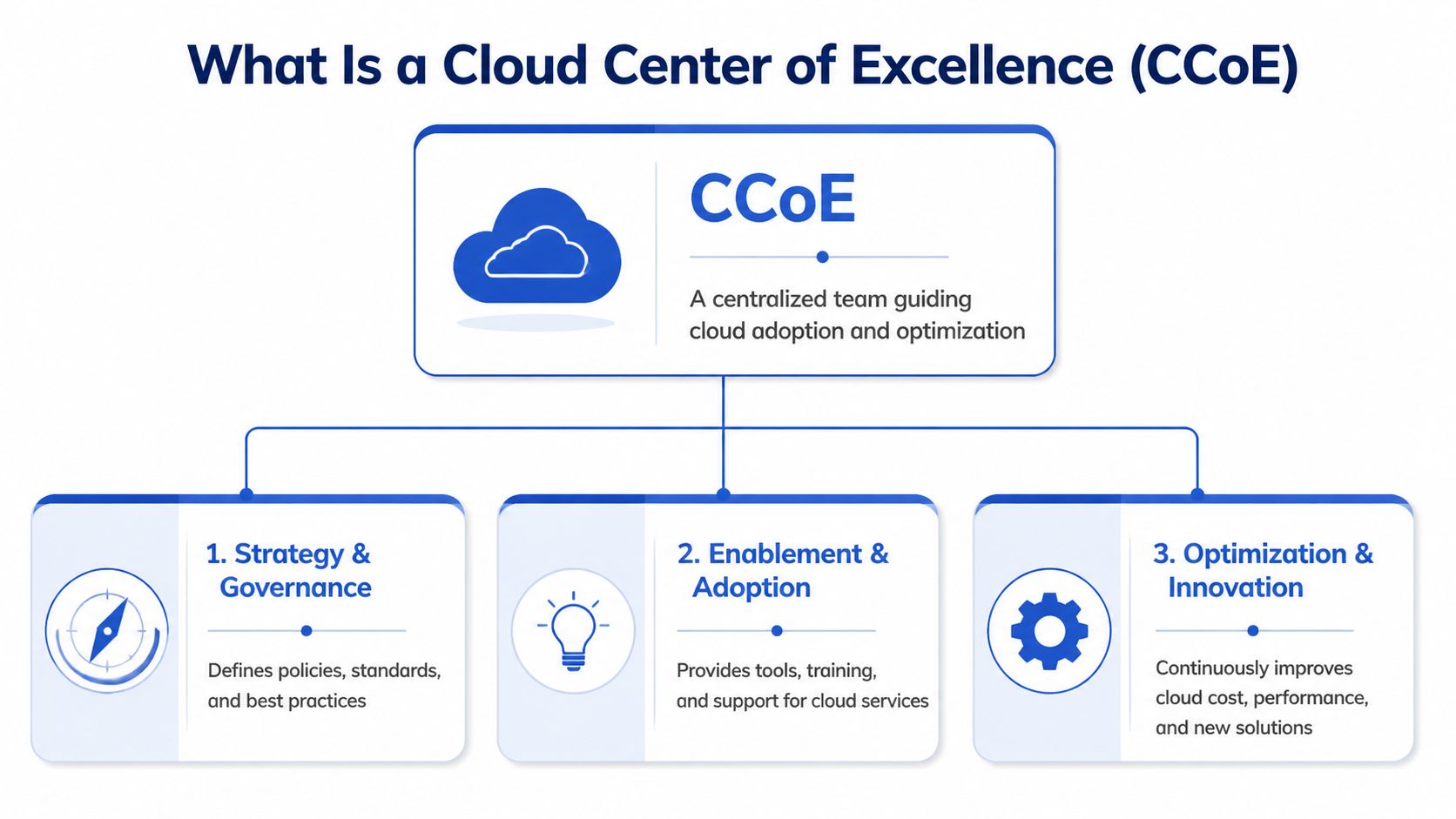
What Is a Cloud Center of Excellence
A cloud center of excellence is a cross-functional team that guides how the business adopts, secures, operates, and improves cloud. The easiest way to explain it is to think of it as a city planning committee for the cloud.
A city planning group doesn't build every house. It sets zoning rules, road layouts, utility access, and safety requirements so builders can work without creating chaos. A CCoE does the same thing for cloud teams. It defines the blueprints, sets the guardrails, and provides shared services so product and engineering teams can build quickly without breaking cost, security, or compliance expectations.
The job is enablement, not gatekeeping
Poorly designed CCoEs become approval machines. Good ones create paved roads.
That means the team should spend more time on reusable templates, guardrails, account patterns, and decision frameworks than on one-off approvals. If engineers have to open a ticket for every policy question, the model is already drifting toward bureaucracy.
A working definition looks like this:
- Strategy and governance: Define account models, naming rules, tagging standards, identity boundaries, and cloud policies.
- Security and compliance: Establish secure defaults for access, logging, encryption, and workload placement.
- FinOps and accountability: Tie cloud usage to teams, products, budgets, and optimization targets.
- Automation and platform support: Build repeatable deployment paths through Infrastructure as Code, policy enforcement, and operational templates.
- Enablement: Train teams, document standards, and support adoption across engineering and non-engineering groups.
What it should own and what it shouldn't
A CCoE should own the standards, shared patterns, and governance model. It shouldn't own every cloud deployment forever.
That distinction matters. Product teams still need to own their applications, service health, and delivery timelines. The CCoE creates consistency around how those workloads are built and run. It acts more like a force multiplier than a command center.
Practical rule: If the CCoE is writing every Terraform module, approving every schedule change, and joining every architecture meeting, it has taken on too much operational ownership.
The four pillars that matter most in SMBs
For SMBs and mid-market firms, the most useful CCoE model usually rests on four pillars:
| Pillar | What it solves | What good looks like |
|---|---|---|
| Governance | Inconsistent decisions | Clear standards that teams can apply without waiting |
| Security | Drift and misconfiguration | Secure defaults built into landing zones and templates |
| FinOps | Unclear ownership and waste | Tagged resources, budget visibility, and routine optimization |
| Automation | Manual work and bottlenecks | Repeatable provisioning, scheduling, and policy enforcement |
The key is keeping the scope tight enough to be useful. A cloud center of excellence isn't an abstract maturity program. It's an operating mechanism for making cloud safer, cheaper, and easier to scale.
The Core Business Benefits of a Strong CCoE
The strongest argument for a cloud center of excellence is not architectural elegance. It's business performance.
Organizations that have implemented a CCoE report meaningful outcomes. 83% say it is effective, and the most cited benefits are reducing security risks at 56%, reducing costs at 50%, and improving agility and innovation at 44%, according to AWS Public Sector's findings from cloud leaders.

Better security because teams stop improvising
A lot of cloud security issues start before anyone writes a detection rule. They start when each team chooses its own access model, logging setup, network pattern, or encryption approach. A CCoE reduces that variability by turning baseline decisions into standards.
That has a direct operational effect. Security teams spend less time chasing exceptions, and engineering teams spend less time guessing what "good" looks like. The business gets a more predictable control environment.
Lower costs because ownership becomes visible
Cloud costs rarely spiral because teams are careless. They spiral because ownership is fragmented. Nobody sees the full picture, and nobody is accountable for the resources that stay running after the need has passed.
A well-run CCoE changes that by forcing decisions around tagging, budget allocation, resource lifecycle, and review cadences. Finance gets cleaner reporting. Engineering gets clearer constraints. Leaders can ask better questions because the data is organized by team and workload, not buried in one account-level invoice.
More agility because the paved road is faster
This is the benefit many teams underestimate. Standardization doesn't slow delivery when it's done well. It removes repetitive decision-making.
A team launching a new service shouldn't have to debate account structure, baseline IAM, approved network patterns, cost ownership, and observability setup from scratch. Those are the conditions a CCoE should pre-decide. When that foundation is in place, teams spend more time building product features and less time re-solving common platform problems.
Here's a useful explainer if your stakeholders want a quick external overview before you formalize the effort:
The practical ROI leaders actually notice
The benefits usually show up in ordinary moments, not in dramatic transformations:
- Fewer architecture arguments: Teams use approved reference patterns instead of debating basics every sprint.
- Cleaner budget reviews: Finance can separate product spend from shared platform spend.
- Faster onboarding: New teams inherit standards instead of building cloud foundations from zero.
- Less policy drift: Security baselines stay consistent as more workloads move to cloud.
The best CCoEs don't create more governance meetings. They create fewer reasons to have them.
Structuring Your CCoE Team and Governance Model
A cloud center of excellence doesn't need a massive headcount. It needs the right mix of authority, technical depth, and business credibility.
In SMBs and mid-market firms, the most common failure isn't under-documentation. It's weak decision rights. Teams are told to "follow standards," but nobody has defined who can approve exceptions, who owns cost controls, or how urgent overrides get handled. That gap matters because, as EdTech Magazine's discussion of cloud centers of excellence notes, delegation frameworks are often underspecified, even though they are critical for balancing central governance with rapid team decisions.
The smallest viable team
You can launch with a lean core if each role has a clear mandate. In a smaller company, one person may cover more than one function. That's normal. What's dangerous is leaving the function unnamed.
| Role | Primary Responsibilities | Key Skills |
|---|---|---|
| Cloud lead | Owns CCoE direction, standards, and executive alignment | Cloud architecture, stakeholder management, policy design |
| Platform architect | Defines landing zones, account patterns, IAM baselines, and deployment templates | AWS or Azure architecture, IaC, networking |
| Security lead | Sets security guardrails, logging, access standards, and exception handling | Cloud security, IAM, audit readiness, risk analysis |
| FinOps owner | Defines tagging policy, budget mapping, chargeback or showback logic, and optimization reviews | Cost analysis, cloud billing, reporting, business communication |
| Operations representative | Aligns reliability, incident workflows, backup standards, and support models | SRE or ops leadership, monitoring, incident response |
| Business or product representative | Brings workload priorities, delivery constraints, and practical adoption feedback | Product operations, delivery planning, cross-functional coordination |
Centralized, federated, or hybrid
There isn't one perfect governance model. The right one depends on how distributed your engineering teams are and how much cloud maturity already exists.
A simple comparison helps:
- Centralized model: Best when cloud adoption is early and skills are uneven. The core team defines standards and keeps tighter control.
- Federated model: Best when several business units already run capable engineering teams. The CCoE sets policy and shared patterns, while domain teams handle implementation.
- Hybrid model: Usually the most practical for mid-market firms. The core team owns standards, landing zones, and guardrails. Product teams own workloads within those boundaries.
For many organizations, hybrid works because it avoids two bad extremes. One is total central control. The other is every team inventing its own cloud operating model.
Delegation rules that prevent bottlenecks
Most guidance on cloud centers of excellence is clear on policy and vague on exceptions. That's a problem because real environments always need overrides.
Use explicit delegation rules for things like:
- Resource schedule overrides for late testing, incident response, or month-end processing.
- Policy exceptions for regulated workloads or vendor-managed systems.
- Temporary access elevation with time-bound approvals and auditability.
- Budget threshold breaches that require product owner acknowledgment before expansion.
Put those rules in writing. Keep them short. Engineers should know when they can proceed, when they need approval, and who gives it.
If an urgent workload change still depends on finding the one cloud expert who knows the unwritten rule, the governance model isn't mature enough.
Tools should support delegation
Governance gets easier when the toolset matches the operating model. Teams need a way to expose the right actions to the right people without handing out full account access. That's one reason many teams evaluate a cloud management platform for shared visibility and controlled actions alongside their broader CCoE design.
The principle is simple. Governance shouldn't require engineers to become ticket processors for basic cost or scheduling decisions. If product managers, ops leads, or service owners can take approved actions safely within policy, the CCoE has done its job well.
A Phased Roadmap to Build and Scale Your CCoE
The fastest way to make a CCoE fail is to launch it as a grand transformation program. Start smaller. Build the operating model in phases, and make each phase solve a visible problem.

Phase one foundation and executive backing
The first phase is not about tooling. It's about clarity.
Define what the CCoE exists to fix in your business. For most SMBs, that's a combination of uncontrolled cloud growth, weak standards, and poor cost accountability. Put that in plain language that both technical and business leaders recognize.
During this phase, lock down four things:
- Mandate: What the CCoE owns, and what remains with product or platform teams.
- Decision rights: Who approves standards, who grants exceptions, and who resolves conflicts.
- Initial scope: Start with one cloud provider, a few high-value workloads, or one business unit if necessary.
- Early success criteria: Choose outcomes that matter, such as cleaner resource ownership, fewer one-off setup decisions, or better shutdown discipline for non-production resources.
Many teams tend to overbuild. They write a charter full of maturity language and never turn it into operating rules. Keep it plain. If a manager can't explain why the CCoE exists after one meeting, the mandate isn't clear enough.
Phase two standardization and the secure landing zone
Once the mandate is real, create the technical baseline. Here, the CCoE starts earning trust.
A core function is establishing a secure landing zone, which is a pre-configured cloud environment with standardized identity, network, logging, and compliance controls. AWS notes that organizations with CCoE-governed landing zones reduce security misconfigurations by over 90% compared to those without, in its guidance on designing a cloud center of excellence.
The landing zone should define:
| Area | Standard to set early | Why it matters |
|---|---|---|
| Identity | Role model, access boundaries, break-glass process | Prevents ad hoc access sprawl |
| Account structure | Environment separation, ownership model, shared services placement | Makes billing and control manageable |
| Networking | Approved patterns for ingress, egress, segmentation | Reduces one-off security decisions |
| Logging | Centralized logs, audit expectations, retention rules | Improves operational and compliance visibility |
| Deployment | IaC templates and approved services | Keeps environments consistent |
Don't wait for perfection. Build the minimum secure baseline that new projects must use, then improve it in iterations.
Start by making the right path the easy path. Teams adopt standards faster when the standard comes with templates, examples, and support.
Phase three optimization and policy-driven cost control
This is the phase many teams delay, and it's a mistake. Cost governance should begin as soon as you have a baseline environment.
At this point, the CCoE should make three things mandatory: tagging standards, budget mapping, and regular optimization workflows. Without those, cost reviews become cleanup work instead of governance.
Examples of practical controls in this phase include:
- Environment-aware schedules: Non-production resources should follow expected working hours unless explicitly exempted.
- Ownership rules: Every compute resource should map to a team or product owner.
- Exception paths: Critical workloads can stay exempt, but exemptions need named ownership and review.
- Review cadence: The CCoE should review cost anomalies and idle resource patterns with engineering and finance together.
Phase four scaling and cultural adoption
Once the operating model works for early workloads, scale it by teaching, not by policing.
That means documenting design patterns, running architecture reviews that coach rather than block, and creating cloud champions inside delivery teams. A mature CCoE becomes a network. The core team still owns standards, but trusted teams absorb more day-to-day decision-making within those boundaries.
Focus on habits that spread well:
- Reference architectures that teams can copy without rework.
- Reusable policy packs for logging, IAM, and deployment controls.
- Onboarding guides for new projects and new managers.
- Simple dashboards that show ownership, risk, and cost posture by team.
A phased roadmap works because each stage gives the business something visible. Better standards. Fewer misconfigurations. Cleaner spend signals. Less decision friction. That's how a cloud center of excellence becomes durable instead of theoretical.
Integrating FinOps and Cost Optimization Practices
Most CCoEs talk about cost control. Fewer operationalize it well.
That gap matters because cost optimization isn't a side activity. It's a governance function. If the CCoE doesn't define ownership, tagging, budget rules, and acceptable automation boundaries, FinOps stays reactive. Teams notice waste only after the invoice lands.
CloudQuery's implementation guidance is blunt on this point. Enterprises without formalized FinOps governance in the CCoE typically waste 20% to 30% of cloud spend, while a more structured model can reduce idle resource costs by 15% to 40% annually through governance-backed optimization workflows, as described in its article on CCoE implementation best practices and pitfalls.
What FinOps looks like inside a CCoE
FinOps inside a cloud center of excellence should answer four operational questions:
- Who owns this cost
- Why is this resource running
- When can it be scaled down or turned off
- What rule or exception keeps it online
Those questions sound simple, but they require structure. A CCoE has to define the tagging taxonomy, cost allocation model, reporting cadence, and override workflow before any optimization tool can help.
A practical FinOps baseline includes:
| Control area | What the CCoE defines | What teams then do |
|---|---|---|
| Tagging | Required fields for owner, environment, product, and cost center | Apply tags consistently in IaC and manual workflows |
| Budgets | Thresholds by team or workload | Review exceptions and planned spikes |
| Scheduling policy | Which resource classes can power down automatically | Opt eligible resources into approved schedules |
| Exception handling | Rules for production, regulated, or time-sensitive systems | Document why exclusions exist |
| Feedback loop | Review rhythm for anomalies and recurring waste | Adjust architecture and usage patterns |
The trap to avoid
Many teams buy cost tools before they settle policy. That usually fails for one reason. The tool can detect idle resources, but it can't decide whether a given system is safe to stop, who should approve the action, or how to expose that action to a non-engineer safely.
That's why governance has to come first. The CCoE creates the policy layer that makes optimization trustworthy.
For data-heavy environments, the same principle applies beyond compute. Teams trying to rein in warehouse and query spend often benefit from tactical guidance like this article on reducing your Snowflake bill, but that guidance works best when the CCoE has already defined ownership and review discipline.
Build cost controls into daily operations
The healthiest model is the least dramatic one. Cost optimization should become part of routine operations, not a quarterly emergency.
Use these habits:
- Turn policy into defaults: Non-production schedules, approved instance families, and baseline shutdown expectations should exist before teams request them.
- Expose the right controls broadly: Product owners and operations leads often need limited actions without full cloud console access.
- Review exceptions regularly: Exemptions tend to linger. Revisit them on a fixed cadence.
- Tie architecture to cost signals: If a workload shows repeated idle patterns, the answer may be scheduling, resizing, or a different deployment model.
A lot of teams also need a shared vocabulary before they can run this well. A concise primer on what FinOps means in practice can help align technical and finance stakeholders around the same operating model.
Cost optimization works when the CCoE treats it as productized governance, not as occasional cleanup.
Measuring Success With CCoE KPIs and Playbooks
A cloud center of excellence that can't show progress won't keep executive support for long. The easiest way to avoid that is to measure outcomes the business already cares about and wrap repeatable work in simple playbooks.
KPIs that actually tell you something
Avoid vanity metrics like number of meetings held or number of policy documents published. Measure whether cloud delivery is becoming more controlled and easier to operate.
Use KPIs across four domains:
| Domain | Useful KPI | Why it matters |
|---|---|---|
| FinOps | Share of resources with complete ownership tags | Shows whether cost accountability is real |
| FinOps | Number of unresolved cost anomalies after review period | Exposes whether the process closes the loop |
| Operations | Time to onboard a new project to approved cloud patterns | Measures enablement quality |
| Operations | Share of workloads deployed through approved templates | Shows whether standards are actually adopted |
| Security | Exceptions to baseline IAM, logging, or network controls | Highlights governance drift |
| Security | Time to close policy exceptions | Indicates whether controls remain temporary |
| Adoption | Number of teams using CCoE playbooks and templates | Shows whether the CCoE is becoming the default path |
| Adoption | Repeat requests for the same architectural clarification | Reveals where guidance is still unclear |
A focused metrics set is easier to manage than an exhaustive one. Teams that want a stronger measurement model often benefit from examples of metrics and KPIs for operational accountability.
Playbook one new project onboarding
This playbook should be short enough that teams will use it and strict enough that standards don't get bypassed.
Trigger: A new application, environment, or major workload enters cloud.
Steps:
- Confirm ownership: Identify technical owner, business owner, and budget owner.
- Classify workload: Production, non-production, regulated, customer-facing, internal.
- Assign landing zone pattern: Place the workload in the approved account and network model.
- Apply baseline controls: IAM roles, logging, encryption expectations, and deployment template.
- Set cost controls: Required tags, budget mapping, scheduling eligibility, and exception status.
- Review before release: Validate that the workload matches baseline policy and document exceptions.
Playbook two cost anomaly response
Cost anomaly handling needs speed and clarity. Long review chains are expensive.
Trigger: Unexpected spend spike, unusual runtime pattern, or budget threshold breach.
Response flow:
- Identify the workload and owner
- Check whether the spike is planned
- Validate tags and recent changes
- Decide on action, which may be scheduling adjustment, rightsizing review, temporary exception, or no action if justified
- Document the root cause
- Feed the finding back into policy or templates
A good playbook doesn't remove judgment. It removes confusion about who acts first and what evidence they need.
What success starts to look like
You'll know the CCoE is working when teams stop treating it as a special program and start treating it as normal cloud operations. New projects use the standard path by default. Cost reviews become less emotional because ownership is visible. Security exceptions become more deliberate and less accidental.
Those are the signals that the CCoE is no longer just a governance body. It's part of how the business runs cloud well.
Conclusion Your CCoE as an Engine for Growth
A cloud center of excellence should make cloud simpler, not heavier. If it becomes a layer of approvals with no operational payoff, it will lose support quickly. If it creates standards, delegation rules, secure defaults, and cost discipline that teams can use, it becomes one of the most valuable operating structures in the business.
The practical path is straightforward. Start with a narrow mandate. Put the right people in the room. Build a secure baseline. Define how cost ownership works before spend gets messy. Create playbooks that reduce ambiguity. Measure whether teams are using the paved road and whether that road is improving cost, security, and delivery.
For SMBs and mid-market companies, this matters even more because there isn't room for waste. Every cloud decision has to support growth, resilience, or both. A well-run CCoE helps leadership get control without strangling speed. It gives engineering clearer patterns, gives finance better visibility, and gives security fewer unknowns.
Start small. Pick one set of standards you can enforce well. Choose one cost workflow you can make repeatable. Build confidence through early wins, then expand. That's how a cloud center of excellence pays for itself.
If your team is ready to turn cloud governance into measurable savings, CLOUD TOGGLE is worth a look. It helps teams reduce cloud spend by automatically powering off idle servers and virtual machines across AWS and Azure, while keeping control practical through role-based access and fast schedule overrides. For organizations building a CCoE with FinOps in mind, that kind of policy-driven automation can make cost optimization easier to operationalize from day one.



