A lot of companies arrive at multi cloud kubernetes the same way. Not through strategy decks, but through friction.
One cloud got you to market fast. Then the bill became harder to predict. A customer asked where data lives. One team wanted a managed database that only one provider handled well. Another team got nervous after an outage review exposed how much of the business depended on a single vendor. None of those problems are unusual. They are what growth looks like when infrastructure choices start affecting revenue, compliance, and operational risk.
Kubernetes becomes attractive at that point because it gives teams one application platform that can run across different providers. But that portability is only useful if you treat multi cloud kubernetes as an operating model, not just a deployment target. The hard part isn't getting a container to run on AWS, Azure, or Google Cloud. The hard part is making networking, identity, deployment policy, and cost control work consistently enough that your engineers don't spend their week stitching together exceptions.
Why Every Business Hits a Cloud Wall
The first cloud decision usually optimizes for speed. That makes sense. One provider, one billing model, one security model, one managed Kubernetes service. Early on, that simplicity is a feature.
Then the wall shows up.
It can look like procurement losing bargaining power because everything is tied to one vendor. It can look like data residency requirements that don't fit your current footprint. It can look like a finance lead asking why environments that no one touched all weekend were still fully powered on Monday morning. For CTOs, these circumstances shift cloud from being merely an engineering choice to a business design problem.

Why companies move past a single provider
Multi-cloud is no longer a niche play for giant platforms. According to the Flexera 2024 State of the Cloud Report, 89% of enterprises now have a multi-cloud strategy, driven primarily by the desire to reduce vendor dependency (53%), manage costs (45%), and improve disaster recovery options (42%), as summarized by Spectro Cloud's review of multi-cloud Kubernetes adoption.
Those drivers matter because they're concrete. They aren't architecture fashion. They map directly to board-level concerns:
- Vendor power: If one provider becomes your only home, negotiation power drops.
- Cost discipline: Different providers are better fits for different workloads.
- Recovery posture: A second cloud can become part of your backup and continuity design.
- Regional fit: Some workloads need to live in specific jurisdictions or near specific users.
If you're building the business case internally, a useful primer on broader infrastructure benefits is Benefits of Cloud Infrastructure for Business. The important nuance is that those benefits don't disappear in a multi-cloud model. They just become harder to govern without a standard platform.
Practical rule: Companies rarely choose multi cloud kubernetes because they want more complexity. They choose it because the business already has complexity, and one cloud no longer absorbs it cleanly.
Why Kubernetes becomes the control layer
Once applications need to run in more than one environment, consistency matters more than provider loyalty. Kubernetes gives teams a shared deployment model, a shared packaging format, and a shared set of operational primitives. That doesn't erase provider differences, but it does stop every application team from solving those differences alone.
The strategic shift is simple. Instead of asking, "Which cloud are we standardizing on?" the better question becomes, "Which operating model lets us use multiple clouds without multiplying operational overhead?" That's why multi cloud kubernetes has become mainstream.
Understanding Multi Cloud Kubernetes
Think of a single-cloud platform as one very large restaurant. One kitchen, one supplier network, one staffing system, one way of doing inventory. You can run it well if everyone knows the rules.
Multi cloud kubernetes is more like running a restaurant chain across different cities. Each location has different landlords, local regulations, utility costs, and delivery routes. If every branch invents its own recipes, training, and procurement process, quality drifts and costs rise. What you need is a central operating manual that keeps the menu, kitchen procedures, and staffing expectations consistent while still allowing each location to work with local conditions.
Kubernetes is that operating manual.
What Kubernetes standardizes
In practice, multi cloud kubernetes means you run Kubernetes clusters across more than one cloud provider, then build your application delivery and operations around that shared platform. Your developers define workloads in Kubernetes objects. Your platform team applies common policies, deployment methods, and observability patterns. The underlying provider still matters, but it matters less to the application team.
That distinction is the point. Application teams shouldn't have to care whether a service lands on EKS, AKS, or GKE every time they ship. They should care about deployment policy, runtime behavior, data dependencies, and service objectives.
A good mental model for this sits close to the core ideas behind Distributed Systems. The system works because you create common behavior across many moving parts, not because every part is identical.
What multi-cloud is not
A lot of confusion comes from related terms that sound interchangeable but aren't.
| Term | What it means | What usually matters operationally |
|---|---|---|
| Single-cloud multi-cluster | Multiple Kubernetes clusters inside one provider | Useful for isolation, environments, or regions, but still one vendor model |
| Hybrid cloud | A mix of public cloud and on-premises infrastructure | Often driven by compliance, legacy systems, or data gravity |
| Multi cloud kubernetes | Kubernetes running across two or more cloud providers | Driven by resilience, commercial flexibility, feature fit, and cost control |
The distinction matters because the operating burden changes. Hybrid introduces private infrastructure concerns. Multi-cluster in one cloud keeps provider semantics mostly stable. Multi cloud kubernetes forces you to confront differences in networking, identity, storage classes, load balancing, and billing.
The best multi-cloud designs don't pretend providers are interchangeable. They create a stable application layer while accepting that infrastructure details still need explicit handling.
The core problem it solves
The true value isn't abstract portability. It's reduced rework.
Without Kubernetes as a unifying layer, every move across providers becomes a partial rewrite of deployment processes, policy enforcement, and runtime operations. With Kubernetes, you still handle cloud-specific pieces, but you stop rebuilding the whole platform every time the business needs a second provider.
That is why multi cloud kubernetes resonates with CTOs. It creates room for commercial and technical choice without forcing every product team to become fluent in every cloud.
Comparing Multi Cloud Deployment Architectures
There isn't one "correct" way to do multi cloud kubernetes. There are several patterns, and each one pushes complexity into a different place. The mistake I see most often is choosing an architecture because it sounds elegant rather than because the team can operate it under pressure.
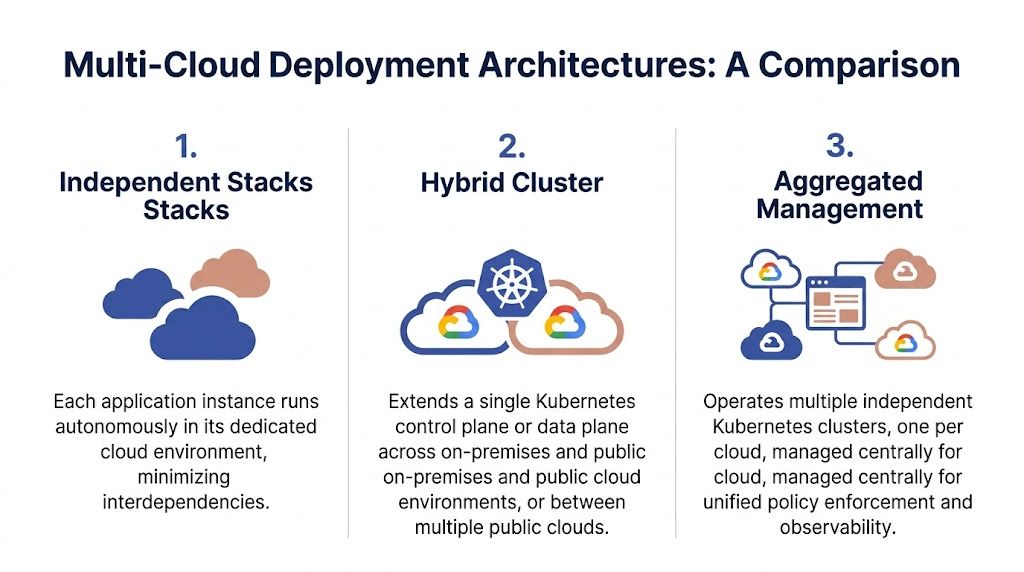
Independent clusters with aggregated management
This is the most practical model for most companies. You run separate clusters in each cloud and manage them through a central layer for policy, visibility, and deployment orchestration.
Each cluster stays close to its provider-native services. Failure domains are cleaner. Upgrades are easier to stage. Teams can roll out common standards without pretending the networks or storage layers are identical.
This approach also keeps blast radius under control. If one cluster has a bad policy push or a provider-specific incident, you don't automatically drag every other environment into the same problem.
Federation-style control across clusters
Cluster federation aims to coordinate multiple clusters through a higher-level control model. In theory, this gives you a cleaner way to place workloads, replicate service definitions, and apply policies across environments.
In practice, it works best when your platform team is strong and your workload patterns are fairly disciplined. Federation can reduce repetitive configuration, but it can also create another abstraction layer that engineers have to debug during incidents. If your team is still struggling with one cluster per cloud, federation won't save you.
Stretched clusters across providers
This is the pattern people ask about because it sounds efficient. One cluster spanning more than one environment. Fewer moving parts on paper. In reality, it's usually where networking pain, latency sensitivity, and operational fragility become visible fast.
A stretched cluster pushes hard problems into the control plane, network paths, and failure handling. It can make sense in narrow cases, but it's rarely the first pattern I'd recommend for a business trying to control risk and spend.
Multi-Cloud Kubernetes Architecture Comparison
| Architecture | Description | Pros | Cons | Best For |
|---|---|---|---|---|
| Independent clusters | Separate Kubernetes clusters per cloud, managed with shared tooling and policy | Cleaner fault isolation, simpler upgrades, strong provider fit | More duplication unless you standardize well | Most SMBs and mid-market teams |
| Federation | Multiple clusters coordinated through a higher-level control approach | Better consistency for placement and policy at scale | Harder debugging, more platform maturity required | Larger platform teams with repeatable workloads |
| Stretched cluster | One cluster spans multiple clouds or environments | Centralized control model | Networking and operational complexity can become severe | Rare edge cases with very specific constraints |
What the tradeoff really is
The strategic question isn't "Which architecture is most advanced?" It's "Where do we want complexity to live?"
- Independent clusters put complexity into platform standardization.
- Federation puts complexity into orchestration and abstraction.
- Stretched clusters put complexity into networking and failure behavior.
For most CTOs, independent clusters are the safest starting point because they preserve optionality without creating an over-coupled platform. If you want a solid business-side overview of this design space, this guide to multi-cloud architecture patterns is a useful companion.
One more point matters here. A key challenge in multi-cloud architectures is integrated networking and multitenancy isolation. Vendor outages, like Google Cloud's accidental deletion of UniSuper's account data which was only recovered from a backup on another cloud, highlight the need for architectures that support 99.99% uptime through diversification, according to Oracle's discussion of hybrid and multi-cluster Kubernetes with KubeSlice.
That example is why I advise clients to evaluate architecture through failure scenarios, not just deployment diagrams. If a provider account issue, network partition, or policy mistake occurs, the architecture has to help humans recover quickly.
Your Operational Guide to Multi Cloud Success
Architecture diagrams are the easy part. The ultimate test of multi cloud kubernetes is whether your teams can operate it on an ordinary Tuesday and during a bad Saturday night incident.
The operational baseline is straightforward. Standardize aggressively where engineers benefit. Accept provider-specific behavior where the underlying platform forces it. Don't chase theoretical purity if it makes day-to-day operations worse.

Infrastructure-as-code integration is a critical operational priority, with 42% of organizations adopting it for multi-cloud Kubernetes. This is followed closely by policy management and guardrail enforcement at 41%, demonstrating a clear focus on automating and standardizing operations across heterogeneous environments, as noted in Gart Solutions' analysis of multi-cloud Kubernetes operations.
Networking that doesn't become its own platform
Cross-cloud networking fails when teams assume pod-to-pod communication should feel as simple as a single-cluster deployment. It won't. Different managed Kubernetes services behave differently. Routing, ingress, DNS behavior, network policy enforcement, and service exposure all vary enough to create hidden operational work.
What works is being deliberate:
- Keep east-west traffic local when possible: If services chat heavily, co-locate them rather than spraying requests across providers.
- Define service boundaries clearly: Cross-cloud links should be intentional, documented, and observable.
- Use overlay or interconnect tools carefully: Products that simplify connectivity can help, but every abstraction adds another incident surface.
If a workload requires constant low-latency chatter between tightly coupled services, that workload is often a poor candidate for being split across clouds.
Field advice: Put portability pressure on deployment and policy, not on chatty runtime traffic. Networks are where elegant multi-cloud plans usually become expensive.
Storage that respects data gravity
Stateless services are the headline story for kubernetes, but real businesses have state. Databases, object stores, queues, search indexes, and file-backed workloads don't become simple just because they're containerized.
A few principles hold up well:
- Treat persistent data as a placement driver. Put compute near the data unless you have a strong reason not to.
- Use CSI-based storage integration where it fits. That keeps Kubernetes workflows consistent even when providers differ under the hood.
- Replicate by business requirement, not ideology. Not every dataset needs active presence in multiple clouds.
- Test restore paths. Backup without restore validation is paperwork.
Many teams over-rotate on workload mobility and under-invest in data recovery discipline. If your restore process depends on tribal knowledge, the architecture isn't mature.
Identity and authorization without drift
Identity is one of the first places multi cloud kubernetes turns messy. Every cloud has its own IAM model, but your engineers still need one understandable way to get access, deploy changes, and audit activity.
The cleanest pattern is to centralize identity above the providers. Use OIDC or another common identity layer for cluster access, then map permissions through Kubernetes RBAC and tightly scoped cloud roles. That gives you one joiner-mover-leaver process instead of several loosely coordinated ones.
What doesn't work is letting every cluster evolve its own permission scheme. That creates two problems fast. Engineers collect excessive rights over time, and nobody can answer a simple audit question with confidence.
A good authorization model usually has these traits:
- Platform-admin roles are narrow and heavily reviewed.
- Application-team roles are namespace or environment scoped.
- Break-glass access exists, but it's audited and time-bound.
- Policy engines such as OPA or Kyverno enforce baseline guardrails consistently.
CI CD that targets any cluster predictably
Multi cloud kubernetes should not require every pipeline to become provider-aware. The deployment process should target clusters through a standard interface, with environment-specific differences handled by configuration and policy, not by duplicated logic.
GitOps tools such as Argo CD or Flux work well here because they create a declarative delivery model. Traditional CI systems can also work if you keep them disciplined. The danger is pipeline sprawl, where every team adds special branching logic for every cluster and every cloud.
A healthier model looks like this:
| Operational area | What to standardize | What can stay provider-specific |
|---|---|---|
| Deployments | Manifests, Helm structure, promotion rules | Load balancer details, storage classes |
| Security | Identity source, RBAC model, baseline policy | Native IAM integration details |
| Observability | Alert format, dashboard taxonomy, incident routing | Cloud-native telemetry connectors |
| Provisioning | Module design, naming, approval workflow | Provider resource implementation |
The operating model that scales
The companies that run multi cloud kubernetes well usually do three things consistently.
- They platformize the boring parts. Cluster bootstrap, policy baselines, observability hooks, and deployment conventions are not left to individual teams.
- They draw a hard line around exceptions. Every provider-specific deviation gets documented, reviewed, and justified.
- They rehearse failure. Access failure, cluster failure, backup restore, policy rollback, and cloud-provider degradation all need runbooks that humans can execute.
The point isn't to remove complexity. It is to contain it so your engineers spend more time shipping and less time translating cloud behavior.
Mastering Multi Cloud Cost and Reliability
Most multi-cloud discussions overemphasize flexibility and underemphasize operating economics. That's a mistake. If you don't build cost control into the design, multi cloud kubernetes becomes an expensive way to duplicate infrastructure mistakes across providers.
Workload placement is a finance decision
Provider diversity only saves money if you place workloads intentionally. Strategic workload placement across AWS EKS, Azure AKS, and Google GKE can yield 30-50% cost reductions by exploiting provider-specific pricing for compute and storage. For example, using AWS Spot Instances for CPU-intensive tasks can offer up to 90% discounts compared to on-demand pricing, according to Apptio's analysis of multi-cloud Kubernetes cost optimization.
That shouldn't be read as "move everything constantly." It should be read as "know which workloads belong where."
Examples that often make sense:
- Batch and interruptible compute can fit spot-backed capacity if the application tolerates interruption.
- Data-heavy services should live where storage and access patterns are most favorable.
- Latency-sensitive customer traffic should stay close to users and dependencies, even if another provider is slightly cheaper on paper.
A mature FinOps model for multi cloud kubernetes starts with visibility by cluster, namespace, team, and environment. If finance can only see cloud spend at the account level, they can't govern behavior that happens inside Kubernetes. If engineering can only see CPU and memory but not the cloud services attached to them, they miss the true cost of operating a service.
For leaders thinking through governance patterns, this overview of multi-cloud management responsibilities is helpful because it frames cost control as an operational capability, not a reporting exercise.
Idle compute is where smaller teams lose money
Large enterprises often have platform teams to build custom cost controls. SMBs and midsize teams usually don't. That gap matters because idle resources are one of the easiest places to waste money in a multi-cloud setup.
Development clusters, test environments, temporary worker pools, and low-traffic internal systems often stay on long after the business stopped needing them. Kubernetes makes this easier to miss because autoscaling creates the impression that all waste is self-correcting. It isn't. If node groups, support services, attached infrastructure, and surrounding virtual machines stay active, spend continues unchecked.
What works in practice:
- Define uptime policy by environment. Production, staging, dev, sandbox, and analytics don't need the same schedule.
- Schedule non-critical capacity off. Nights, weekends, and known idle windows should be explicit.
- Separate critical from non-critical workloads. If everything shares the same nodes, nothing can be shut down safely.
- Give finance and engineering one review view. Cost anomalies need shared ownership.
A lot of "optimization" efforts fail because teams focus on rightsizing and ignore scheduling. Rightsizing helps. But if no one uses an environment for long stretches, the best optimization is often turning it off.
This walkthrough adds useful context before teams over-tune autoscaling settings:
Reliability and cost are linked. The more undifferentiated infrastructure you keep running, the harder it becomes to see which systems are actually business-critical.
Reliability without blanket duplication
Reliability in multi cloud kubernetes does not mean running every workload everywhere all the time. That is the fastest route to runaway spend.
A better model is selective redundancy. Put true revenue-critical services behind failover and recovery patterns that justify the cost. Keep backups, restore processes, and deployment portability strong enough that lower-tier systems can recover without permanent warm duplication. The goal is resilient service design, not symmetry for its own sake.
Essential Tooling for Multi Cloud Management
A strong multi-cloud operating model depends less on one miracle platform and more on using the right tools for each control layer. Tool sprawl is still a risk, so the selection standard should be simple. Every tool needs to reduce complexity that humans would otherwise carry.
Cluster management and policy control
Teams typically begin with platforms such as Rancher and Spectro Cloud, which give operators a central way to manage multiple Kubernetes clusters, apply policy, and maintain some consistency across cloud boundaries. That central view matters because unmanaged cluster growth is how standards drift.
The mistake is assuming a management console solves the underlying discipline problem. It doesn't. You still need clean cluster templates, clear ownership, and a promotion model for policy changes. The console helps enforce. It doesn't invent order.
Cost visibility and optimization
For Kubernetes cost management, tools like Kubecost and Finout help connect cloud spend to workloads and teams. That attribution is the difference between vague complaints about cloud cost and actionable decisions by namespace, service, or environment.
The gap gets wider for smaller organizations once idle resource control enters the picture. A common gap in multi-cloud coverage is practical guidance for SMBs on managing idle resources. While enterprise case studies show 40% overhead reduction, they often rely on complex IaC setups, overlooking the need for intuitive, shared-access tools for non-engineers to schedule precise daily or weekly power-offs on transient workloads, as discussed in Bacancy Technology's review of multi-cloud Kubernetes cost challenges.
That point matters because many companies don't need a bigger automation framework first. They need a safer way to stop paying for compute no one is using. If your team is evaluating when autoscaling is enough versus when scheduling should enter the picture, this guide to cluster autoscaler tradeoffs is worth reviewing.
Observability across clouds
Prometheus and Grafana remain practical building blocks for federated observability. They work well when you standardize metric names, dashboard layout, and alert ownership. They become painful when every cluster gets its own homegrown dashboards and nobody agrees on service health indicators.
A useful observability stack in multi cloud kubernetes should answer four questions quickly:
- What failed
- Where it failed
- Who owns it
- What changed recently
If your tooling can't answer those questions without opening three provider consoles and several ad hoc dashboards, the stack isn't integrated enough.
Security and guardrails
OPA, Kyverno, and admission controls are the practical layer for policy enforcement inside Kubernetes. They help teams stop insecure or non-compliant patterns before they land in clusters. In multi-cloud environments, that consistency is more valuable than any single provider-native security feature because the policy follows the platform rather than the account.
The best toolsets don't try to hide all provider differences. They make the differences explicit, controlled, and auditable.
Frequently Asked Questions
How should we handle container image registries across clouds
Keep image distribution close to where workloads run. If one central registry creates slow pulls, extra transfer costs, or brittle cross-cloud dependencies, replicate strategically. The key is consistency in image promotion and signing, not forcing every cluster to pull across the same path. A primary registry process and cloud-local mirrors or pull-through options prove effective where needed.
Do we need a service mesh on day one
Usually, no. A service mesh helps when you need advanced traffic policy, mTLS between services, or fine-grained cross-cluster routing controls. It also adds operational surface area. If your team is still standardizing ingress, DNS, identity, and baseline observability, adding Istio or Linkerd too early can slow you down. Start when the networking and security problems are real enough to justify another control plane.
What's the safest way for a small team to start with multi cloud kubernetes
Don't begin with active-active production across providers. Start with one primary cloud and a second cloud used for a narrow purpose. Good examples include a non-production cluster, a disaster recovery target, or a specific workload class that benefits from provider differences. Keep the first goal modest. Prove that your deployment model, identity model, and cost reporting work across both environments before you broaden scope.
What usually breaks first
Not Kubernetes itself. Operations do. Access drift, inconsistent policies, weak tagging, unclear ownership, and missing cost accountability show up before scheduler mechanics become the issue. That's why the operating model matters as much as the architecture.
If your team is trying to reduce cloud waste without handing full cloud-console access to everyone, CLOUD TOGGLE is worth a look. It helps organizations schedule and power off idle servers across providers, apply role-based access controls, and give non-engineers a safe way to contribute to cost savings. For SMBs and mid-market teams, that's often the fastest path to predictable savings while broader multi-cloud kubernetes practices mature.



