Trying to get a handle on your cloud spending is a top priority for almost every business these days, but it’s frustrating when the bills just keep climbing. This often happens because the very flexibility that makes the cloud so powerful, spinning up new resources in minutes, can easily lead to runaway spending if you're not keeping a close eye on things.
The trick is to stop reacting to surprise bills and start building a culture of cost awareness from the ground up.
Why Your Cloud Bills Keep Growing

Cloud spend has a nasty habit of spiraling out of control, turning a powerful asset into a major financial headache. This isn't just about paying too much; it's about how that unchecked spending eats into your budget for innovation, hurts profitability, and distracts your team from work that actually matters.
The first step to getting things back on track is understanding what’s really going on.
Many companies jump into the cloud for its agility but forget to bring the financial discipline needed to manage it well. Teams can launch new resources with just a few clicks, which is great for speed, but without solid oversight, those resources often stick around long after they're needed. This is the classic "cloud waste" problem, paying for idle or oversized infrastructure that isn't delivering any value.
The Real Reasons for Escalating Costs
A few common culprits are almost always behind rising cloud bills. One of the biggest offenders? Non-production environments. Think about all your development, testing, and staging servers that are left running 24/7. Most of the time, they’re only being used during business hours, which means you’re just burning cash the rest of the time.
Another major driver is the absence of clear governance. When you can't easily track who owns which resource or why a service was provisioned in the first place, it’s nearly impossible to make any meaningful cost reductions. You can’t fix what you can’t see.
Here are the key drivers we see time and time again:
- Idle Resources: This is the low-hanging fruit. Dev and staging servers, databases, and other resources running overnight and on weekends when nobody is working.
- Overprovisioning: It's tempting to allocate more compute or storage than an application needs "just in case," but that buffer comes at a steep price for unused capacity.
- Lack of Visibility: When costs are buried across different projects, teams, or accounts, you have no way of spotting the big savings opportunities hiding in plain sight.
The core issue is often a disconnect between engineering freedom and financial accountability. Empowering teams to build quickly is essential, but it has to be balanced with smart, automated controls that keep things efficient.
That's exactly what this guide is about. We're going to walk through practical, automated solutions that tackle these challenges head-on. By putting smart scheduling and governance in place, you can build a cost-conscious culture without slowing down your developers one bit.
Eliminate Waste with Automated Scheduling

One of the quickest wins for cutting down your cloud bill is going after idle resources. It's a surprisingly common problem, a huge chunk of wasted spend comes from non-production environments like development, staging, and testing servers just sitting there running 24/7.
But think about it. Those resources are usually only needed during business hours. That means you could be paying for 100+ hours of idle time every single week.
Automated scheduling is the simplest, most direct way to fix this. The idea is basic: you set a schedule to automatically power down resources when nobody's using them and fire them back up when they're needed. This one change can deliver an immediate, significant drop in your costs with very little fuss.
Identifying Your Scheduling Opportunities
First things first, you need to figure out what to schedule. This means taking a look at your team's usage patterns to find the perfect on and off times. Most development and QA teams stick to a standard Monday to Friday, 9-to-5ish schedule, which makes their environments prime candidates for scheduling.
You’ll want to look for environments with these traits:
- Predictable Usage: Resources that are consistently used during specific hours or days.
- Non-Critical Workloads: Think dev, staging, and UAT servers. They absolutely do not need to be online all the time.
- Team-Specific Resources: Environments tied to a specific team that works on a set schedule.
By pinpointing these resources, you can build a baseline schedule that mirrors your team's actual work hours. For a typical team, that might mean running resources from 8 AM to 6 PM on weekdays and shutting them down completely over the weekend. Just doing this can slash costs on those specific resources by up to 70%.
Implementing a basic "off-hours" shutdown policy is often the fastest path to meaningful savings. It doesn't require complex architectural changes, just a clear understanding of when your resources are actually providing value.
Choosing the Right Scheduling Tool
Once you have your targets lined up, it's time to put a plan into action. You've got a few options here, ranging from the tools built into your cloud provider's platform to more specialized third-party solutions.
Native tools like AWS Instance Scheduler or Azure Start/Stop VMs v2 can handle basic scheduling. They’re a decent starting point, but they often demand more complex setup, scripting know-how, and ongoing maintenance. Plus, managing who has access can get tricky, as you might have to grant broader permissions than you're comfortable with.
On the other hand, third-party platforms like Cloud Toggle offer a more direct and user-friendly route. These tools are built from the ground up for cost optimization, giving you an intuitive interface to create and manage schedules without needing to be a cloud expert.
For a detailed walkthrough on setting up schedules effectively, our comprehensive Cloud Toggle scheduling guide provides step-by-step instructions.
The real advantage of a specialized platform is its simplicity and security. You can empower team leads, or even non-technical staff, to manage their own schedules safely, without throwing them into the deep end of your cloud account. This is how you start building a culture where everyone feels responsible for cost efficiency.
Build a Strong Cloud Governance Framework
Automated scheduling is a fantastic tactic for a quick cost win, but it's only one piece of the puzzle. If you want to create lasting savings, you need a strong governance framework that builds cost-conscious habits across your entire organization. Without clear rules, cloud environments quickly spiral into chaos and become incredibly expensive.
A solid governance framework is about being proactive, not reactive. It gives you the visibility and control to manage resources effectively from the start, making sure every dollar you spend on the cloud delivers real value. It’s the difference between frantically cutting costs after the bill arrives and managing your finances intelligently from day one.
The demand for this kind of structured approach is booming. The global market for cost reduction services is expected to jump from an estimated USD 123.6 million in 2025 to USD 242.4 million by 2032. That’s a massive increase, and it’s all driven by the urgent need to get operational expenses under control.
Establish Foundational Governance Policies
First things first, you need to implement a few essential policies that provide immediate clarity and control. Think of these as the bedrock of your cost optimization strategy, they're crucial for preventing those nasty budget surprises.
Here are the three core components you should start with:
- Tagging Policies: Make tagging mandatory for every single resource. Tags are just simple key-value pairs, but they're incredibly powerful. They let you track costs by project, team, or application, so you can see exactly where your money is going.
- Spending Alerts: Set up automated alerts that fire off a notification when spending in an account or on a specific service crosses a line you define. This early warning system helps you catch unexpected cost spikes before they blow up your budget.
- Role-Based Access Control (IAM): Use Identity and Access Management (IAM) to lock down who can create, modify, or delete resources. Limiting permissions to only what’s necessary for someone's job is a simple but incredibly effective way to prevent unauthorized or accidental resource provisioning.
A strong tagging policy isn't just a "nice-to-have," it's non-negotiable. It is the single most important element for actually seeing what you're spending. Without it, you’re flying blind and can't possibly attribute costs or spot opportunities to save money.
Automate Enforcement with Policy as Code
Trying to enforce these rules manually across a growing environment just isn't going to work. It’s not scalable. This is where policy as code becomes your best friend. Tools like AWS Config or Azure Policy let you define your governance rules directly in code.
For example, you could write a policy that automatically flags, or even terminates, any new virtual machine launched without the required "Project" tag. This kind of automated enforcement ensures your rules are followed consistently, 24/7, without your team having to constantly police the environment.
This structured, automated approach is a core principle of FinOps, a discipline that brings financial accountability to the cloud's variable spending model. If you want to dive deeper, check out our guide on what FinOps is and how it helps organizations manage their cloud costs. By building a strong governance framework, you’re not just saving money; you’re creating a culture of accountability that drives sustainable cost reduction.
Use On-Demand Environments for Peak Efficiency
While automated scheduling is a huge leap forward, you can unlock even deeper cost reductions by shifting to a fully on-demand model.
This technique, sometimes called Cloud Toggling, goes beyond fixed schedules. It empowers your teams to spin up entire environments only when they need them for a specific task and then automatically tear them down right after. This simple change almost completely eliminates idle time.
Imagine a developer who needs a full staging environment to test a single feature. With scheduling, that environment might run for a standard eight-hour workday. But with an on-demand system, they can provision it, run their tests for two hours, and then destroy it. The result? You only pay for the two hours it was actively used.
This strategy gives your team ultimate flexibility while driving down costs far more aggressively than scheduling alone.
Building Your On-Demand System
Creating an on-demand workflow is more accessible than you might think. It doesn't require a massive engineering effort. Instead, you can build a powerful and user-friendly system by combining a few key tools your teams probably already use.
The core components of a great on-demand system usually include:
- Infrastructure as Code (IaC): This is non-negotiable. Tools like Terraform or AWS CloudFormation are essential for defining your environments in code. This ensures you can create and destroy them reliably and repeatedly with a single command.
- Automation Server: A CI/CD pipeline or a tool like Jenkins acts as the engine. It's the brains of the operation, running the scripts that execute your Terraform plans to build or tear down the environment on command.
- ChatOps Integration: This is the magic that makes the whole system so easy to use. By integrating with a platform like Slack or Microsoft Teams, developers can run a simple command like
/deploy-staging-feature-branchto get the resources they need without ever leaving their chat window.
The real power of on-demand environments is how they shift the mindset from "always on" to "on when needed." This change fundamentally alters how your teams consume cloud resources, making efficiency the default behavior rather than an afterthought.
How On-Demand Drives Savings
The primary benefit is, of course, a dramatic reduction of cost, particularly for non-production environments.
Instead of paying for an environment to run for 168 hours a week, you might only pay for the 10 or 20 hours it was actually in use for development, testing, or demos. This is a game-changer for environments that aren't needed daily, like setups for user acceptance testing (UAT) or performance testing.
The decision tree below shows how foundational governance practices are the bedrock for advanced cost-saving strategies like on-demand environments.
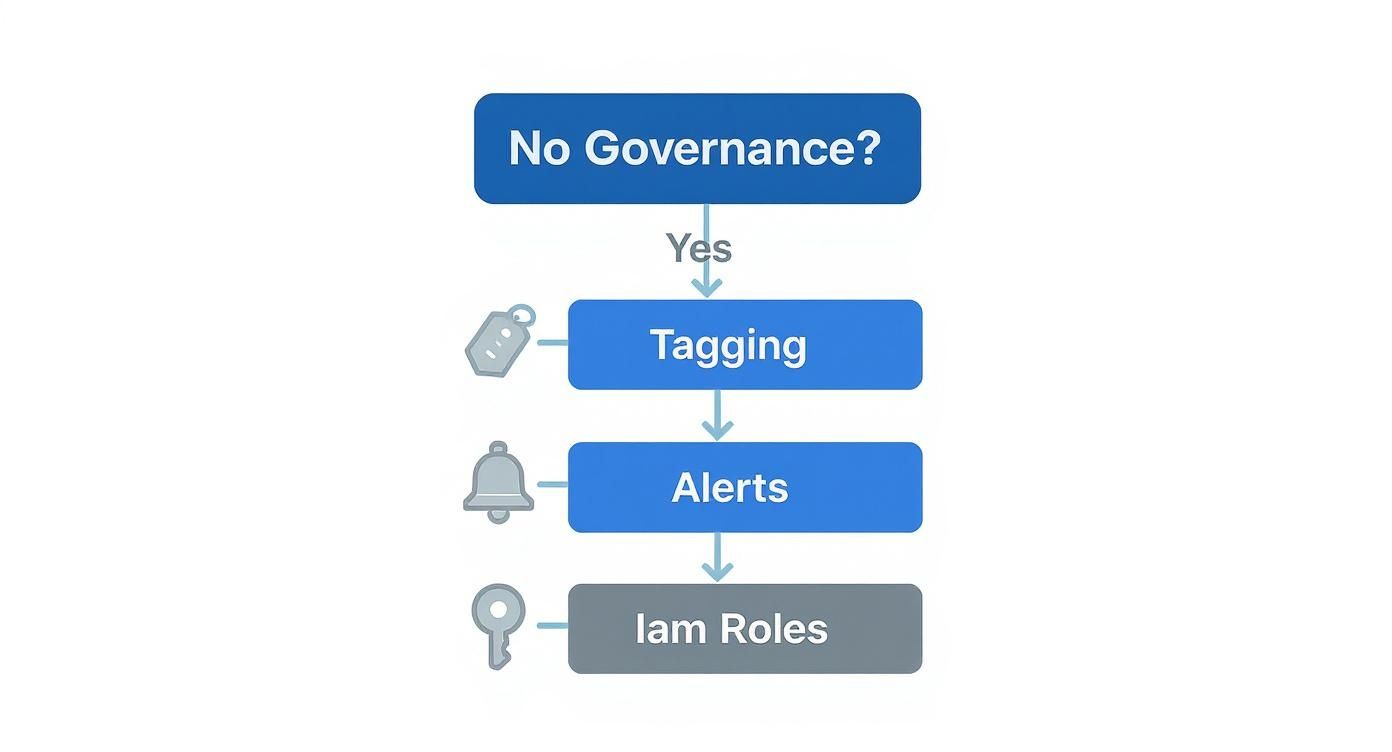
As the infographic makes clear, without basic governance like proper tagging and role-based access controls, trying to implement sophisticated, automated cost controls is nearly impossible. You have to walk before you can run.
This approach also boosts productivity. Developers no longer have to wait for a shared environment to become available or deal with configuration drift from someone else's project. They get a clean, isolated environment for every task, leading to faster, more reliable testing cycles. By combining smart tooling, you create a self-service system that empowers developers while keeping your cloud bills lean.
Scheduling vs On-Demand Toggling for Cost Reduction
Choosing between automated scheduling and a full on-demand model depends on your team's workflow and the predictability of your resource needs. While both are powerful cost-saving tactics, they solve slightly different problems.
| Feature | Automated Scheduling | On-Demand Toggling |
|---|---|---|
| Best For | Predictable workloads, like dev environments used 9-to-5. | Unpredictable, task-based workloads like QA, demos, or bug fixes. |
| Cost Savings | Good; eliminates off-hours waste (up to 70%). | Excellent; eliminates all idle time, paying only for active use. |
| Implementation Effort | Low to moderate. | Moderate; requires IaC and automation pipelines. |
| User Experience | Seamless; resources are "just there" during business hours. | Requires user action (e.g., a Slack command) to provision/destroy. |
| Flexibility | Rigid; follows a fixed schedule. | Highly flexible; environments created and destroyed as needed. |
Ultimately, many organizations find success using a hybrid approach. You might use scheduling for your core development environments that see consistent daily use, while implementing on-demand toggling for more specialized or temporary needs like staging, UAT, and performance testing. This combination provides a powerful, multi-layered strategy for optimizing your cloud spend.
Design a More Cost-Effective Cloud Architecture

While scheduling and on-demand environments are great for tackling operational waste, the real secret to long-term cost reduction is building efficiency directly into your cloud architecture. Proactive design choices stop overspending before it starts, creating a foundation that’s both powerful and economical.
This is about moving beyond reactive fixes and thinking critically about how you build and run your applications from day one.
One of the most powerful practices you can adopt is right-sizing. In simple terms, this means constantly analyzing your virtual machines' performance and matching their instance types to what the workload actually needs. It’s incredibly common for teams to overprovision resources "just in case," a habit that means you're perpetually paying for CPU and memory you just don't use.
By using monitoring tools to track your utilization metrics, you can confidently downsize oversized instances without hurting performance. The result is immediate and recurring savings.
Modernize with Serverless and Containers
Beyond tuning individual machines, you should look at modern architectural patterns that are inherently more cost-effective. Legacy applications often lean on big, monolithic virtual machines that are expensive to run and scale. Moving to serverless or container-based architectures can fundamentally change your cost structure for the better.
Here’s a quick look at how they help:
- Serverless Computing: With platforms like AWS Lambda or Azure Functions, you only pay for the exact compute time your code uses, right down to the millisecond. No more paying for idle servers. This approach is perfect for event-driven services or applications with sporadic traffic.
- Containers: Tools like Docker and Kubernetes let you pack your applications more densely onto fewer virtual machines. This immediately improves resource utilization and makes scaling much simpler, ensuring you aren't wasting precious capacity.
These methods don't just lower your direct infrastructure costs; they also slash the operational overhead of managing servers. You can dive deeper into how these concepts compare in our guide on horizontal vs vertical scaling.
The most effective cost optimization strategy is to stop paying for idle resources altogether. Serverless and containerization get you closer to that ideal by tightly coupling your spending to actual application demand.
Optimize Your Data Storage Costs
Data storage is another area just begging for architectural optimization. Not all data is created equal, and your cloud provider knows this, offering different storage tiers at wildly different price points based on access frequency. Storing old logs, backups, or archival data in a high-performance tier is like paying for a sports car just to let it collect dust in the garage.
By creating a data lifecycle policy, you can automatically shuffle less-needed data to cheaper storage tiers. For example, you could keep fresh data in a standard tier for 30 days, then move it to an infrequent access tier for six months, and finally shift it to a long-term archival service like Amazon S3 Glacier or Azure Archive Storage.
This tiered approach guarantees a significant reduction of cost without sacrificing data availability when you actually need it. This mindset aligns perfectly with how top executives are using process optimization and technology to tackle operational inefficiencies and drive cost reduction in 2025.
The Future of AI in Cloud Cost Management
The next chapter in cloud cost optimization is a big one. We're moving away from poring over spreadsheets and setting rigid, static rules. Instead, the focus is shifting toward intelligent, data-driven insights powered by artificial intelligence. AI is changing the game entirely, turning cost management from a reactive cleanup job into a proactive, predictive discipline.
AI-powered tools are uniquely capable of crunching massive volumes of usage data, finding savings opportunities that are just about impossible for a human to spot. For example, they can accurately forecast future consumption patterns to recommend the perfect Savings Plan or Reserved Instance purchase. This means you commit to the right level of spending without the guesswork and risk of overprovisioning.
Proactive Anomaly Detection
One of the most powerful applications of AI is in real-time anomaly detection. Think of it like a smart smoke detector for your cloud bill. Machine learning models learn the normal, day-to-day spending rhythm of your environment and can instantly flag anything that deviates from that baseline.
This gives you a heads-up the moment problems like resource leaks, critical misconfigurations, or even unauthorized activity start to happen. Catching these issues early stops them from snowballing into a shocking end-of-month bill. It's a critical safety net for your budget, making cost reduction an automated, continuous process.
The real magic of AI here is its ability to move beyond just looking at historical data and actually start forecasting. It answers the question, "What will my costs look like next month?" and, more importantly, helps you take action today to shape that outcome.
Intelligent Resource Optimization
Beyond just flagging problems, AI can actively recommend the fix. Modern optimization engines use machine learning to suggest specific, actionable steps, such as:
- Right-sizing recommendations that go deeper than just CPU usage, analyzing a whole range of performance metrics.
- Identifying "zombie" resources, the ones that are provisioned and costing you money but show zero signs of actual use.
- Predicting workload spikes to help you scale resources up and down with much greater precision and efficiency.
This level of intelligence is a huge leap forward for cost management. The impact of AI on operational expenses is already being felt across many industries. In banking, for example, the effective integration of AI has the potential to slash certain operational costs by as much as 70%. You can dig deeper into how AI is reshaping financial models at McKinsey.
As this technology becomes more accessible, it's quickly becoming the standard for any serious cloud cost optimization strategy. This kind of intelligent automation is the key to managing today's complex, dynamic cloud environments and achieving a sustainable reduction of cost.
Ready to stop paying for idle cloud resources? CLOUD TOGGLE makes it easy to automate your savings with intuitive scheduling and on-demand controls for AWS and Azure. Start your free 30-day trial and see how much you can save at https://cloudtoggle.com.



